

In the modern data-driven enterprise, PostgreSQL is the undisputed workhorse. From high-frequency trading platforms to AI-driven agentic workflows, it anchors the most critical applications. However, as datasets swell into the terabytes, a persistent, costly friction emerges: the "storage tax." Organizations are forced to choose between the high cost of keeping aging data in primary PostgreSQL storage or the operational nightmare of migrating it to "cold" archives that are often siloed, read-only, or incompatible with standard SQL.
Today, the pgEdge team, led by lead engineer Jimmy Angelakos, is changing that calculus with the release of pgEdge ColdFront v1.0.0-beta1. ColdFront introduces a paradigm shift in data lifecycle management: a transparent, fully writable, open-source data tiering solution for PostgreSQL that requires zero application code changes. By uniting OLTP, analytics, and AI workloads under a single interface, ColdFront aims to eliminate the artificial boundaries that have historically hindered data architecture.
The Economics of Aging Data
To understand the significance of ColdFront, one must look at the "trade-off" that has defined database administration for the last decade.
For a financial institution, regulatory mandates often require seven years of transaction history. While a table may reach 4 TB in size, the "hot" data—the information actively queried—rarely exceeds the last 90 days. Under traditional models, the remaining 3.7 TB sits in the primary PostgreSQL heap, inflating cloud storage bills, ballooning backup windows, and creating massive overhead for routine VACUUM operations.
Until now, the alternatives have been grim. Archiving data to a cheaper tier usually renders it "dark"—inaccessible to standard SQL queries. If a GDPR deletion request arrives for a customer whose data has been archived, engineers face an arduous, half-day operation: restoring the archived partition to hot storage, executing the deletion, re-archiving the data, and verifying the integrity of the storage.
In the era of AI governance, this inefficiency is more than an annoyance; it is a critical failure point. As autonomous agents generate massive logs of decision traces, the need for provenance is absolute. If a bad agent decision is traced back to a stale record, the provenance team must be able to correct that record immediately. If that source record is trapped in a read-only archive, the correction loop breaks, leaving the organization vulnerable to compliance breaches and flawed AI outcomes.
A Landscape of Compromise: The Competitive Context
The "Postgres-lakehouse" ecosystem has seen rapid expansion, yet each existing solution demands a sacrifice of core principles.
- EDB’s Postgres Analytical Accelerator (PGAA): Requires proprietary distribution and a minimum three-node cluster. Because the cold tier is read-only, corrections demand a costly round-trip to the hot heap. Furthermore, it relies on an external analytical engine (Seafowl) communicating over Arrow Flight RPC.
- Databricks Lakebase: A managed-only fork that prohibits self-hosting. It utilizes a proprietary, chunked format for cold pages, creating a "one-way mirror" where data is readable by Databricks’ Photon engine but invisible to PostgreSQL itself.
- Snowflake’s pg_lake: While it offers writable Iceberg tables, it forces a split-brain architecture where hot and cold data reside in tables with different names. Application developers are burdened with the logic of routing queries, and the stack relies on a complex web of 15+ extensions and a separate DuckDB daemon.
Each of these vendors offers powerful technology, but they all necessitate a departure from the "PostgreSQL way." They demand you trade your ability to self-host, your ability to write to historical records, or the transparency that keeps your application code clean.
ColdFront: A New Architecture for Data Tiering
ColdFront rejects the premise that you must choose between cost-efficiency and operational simplicity. Built on the principle of transparency, ColdFront operates on stock, upstream PostgreSQL 17 and 18. There is no proprietary fork, no forced migration, and no hidden daemon architecture.
The Mechanics of Transparency
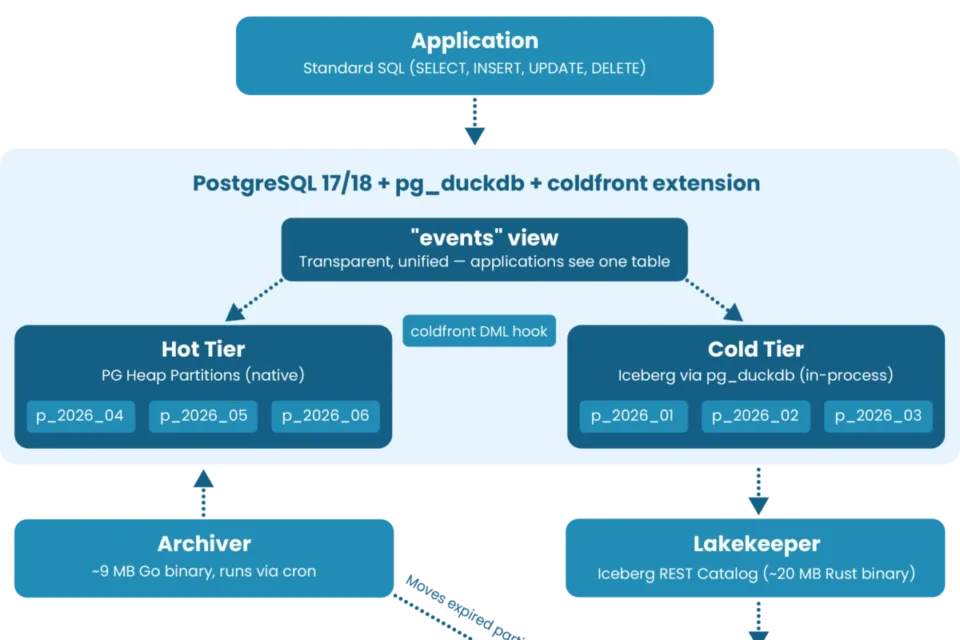
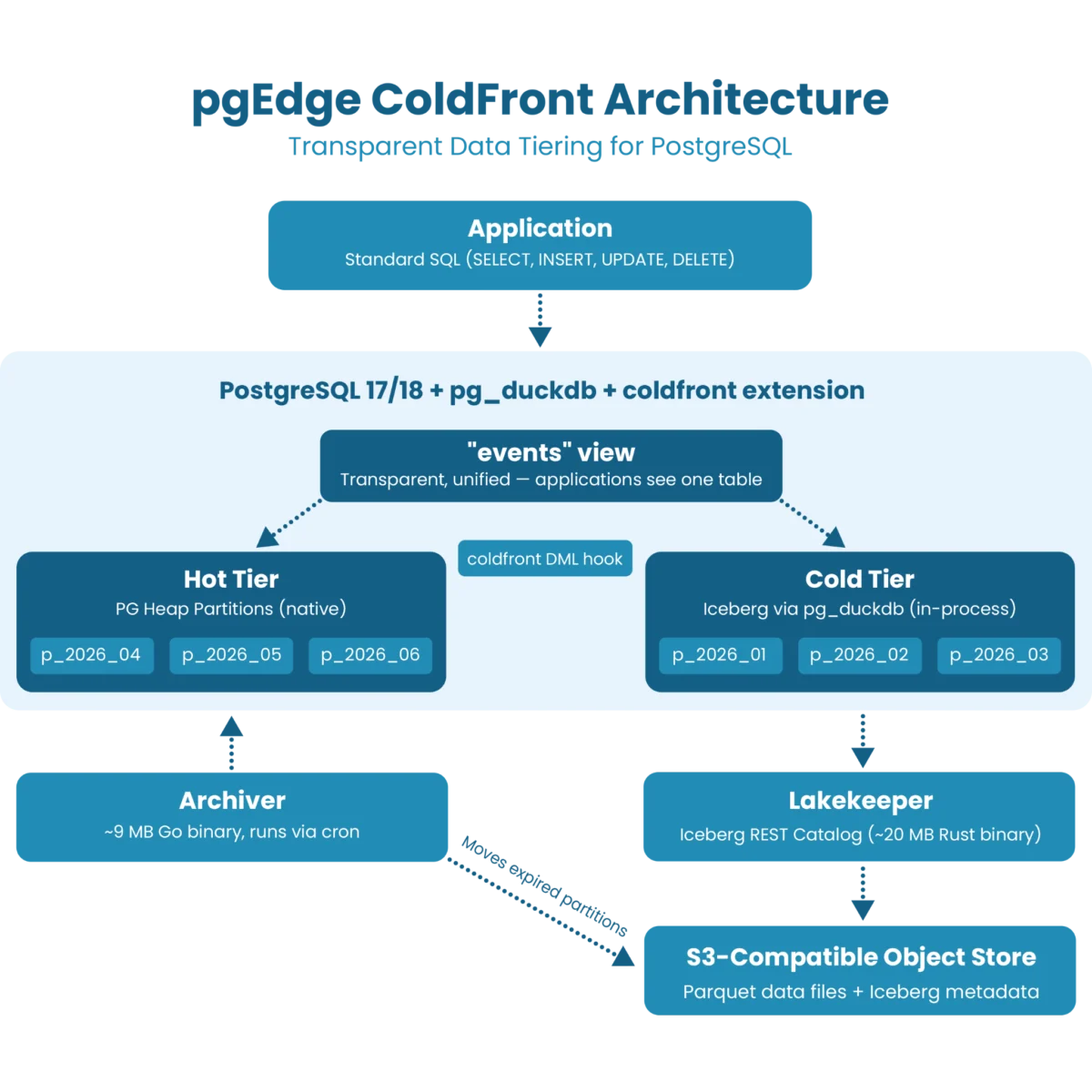
ColdFront operates through two primary extensions loaded at startup: pg_duckdb for high-performance, in-process Iceberg I/O, and coldfront for DML (Data Manipulation Language) rewrite hooks.
The system intercepts queries at the planner level. If an application executes a SELECT, UPDATE, or DELETE, the C-level extension determines which tier the data resides in and routes the operation accordingly. The application remains entirely agnostic of the storage tiering; to the developer, it is just another table in the database.
The Power of the Writable Cold Tier
The headline feature of version 1.0.0-beta1 is its fully writable cold tier. By allowing UPDATE and DELETE operations on archived rows via the standard interface, ColdFront transforms a half-day ops nightmare into a single SQL statement.
For organizations that require strict immutability, ColdFront provides a "Grand Unified Configuration" (GUC) to enforce read-only status on cold data. However, for the majority of real-world use cases—where data errors occur and corrections are mandatory—the writable model is the default, ensuring that data lifecycle management never becomes an obstacle to data integrity.
Distributed Cold Writes via Spock
Perhaps the most technically impressive aspect of ColdFront is its handling of distributed environments. Utilizing a bakery protocol model-checked in TLA+ and based on the Lamport/Ricart-Agrawala algorithm, ColdFront serializes Iceberg commits across nodes.
This enables multiple PostgreSQL nodes in a pgEdge Spock mesh to write to the same Iceberg table concurrently without 409 conflicts or application-level retries. In validation testing, throughput scaled linearly, moving from 2.4 million rows per second on three nodes to 4.2 million on five. This is the only architecture currently available where any node in a distributed mesh can directly modify archived data.
Supporting AI Governance and Provenance
The rise of "context-heavy" AI architecture—where agents require access to both real-time data and historical provenance—demands a database that can bridge the gap.
As AI platforms like Galileo, Arize, and LangSmith standardize the way we monitor agent behavior, the underlying data infrastructure must evolve. ColdFront is uniquely positioned to handle this. Because it uses DuckDB in-process, it provides columnar-engine analytical performance on historical Parquet data, while hot-tier partition pruning maintains index-level speed for recent records.
When an AI provenance team needs to investigate a decision trace from six months ago, they can query the entire dataset in a single round-trip. If a source record requires correction to fix a bias or a factual error, the team can issue an UPDATE directly. The correction is immediate, auditable, and requires no data movement. This capability directly supports the EU AI Act’s requirements for rigorous data quality and provenance standards.
Implications for the Future
The release of ColdFront marks a transition in how we view database storage. By decoupling the physical storage layer from the logical SQL interface without forcing a proprietary vendor lock-in, pgEdge is effectively "commoditizing" the benefits of lakehouse architecture.
Strategic Advantages
- Open Standards: By leveraging Apache Iceberg and standard Parquet files, ColdFront ensures that data remains portable. Should a team decide to move away from ColdFront, their cold data remains accessible by any standard Iceberg-capable tool.
- Operational Consistency: Because ColdFront runs on standard Linux distribution packages, it integrates seamlessly with existing
pg_dump, logical replication, and monitoring workflows. - Partition Lifecycle Automation: Beyond just tiering, ColdFront automates the entire lifecycle: pre-creating partitions, moving aged data to cold storage, and expiring data per policy. It can even function as a standalone, high-performance partition manager, solving long-standing issues with single-column primary keys in time-partitioned tables.
Moving Forward: The Path to Adoption
ColdFront 1.0.0-beta1 is available today via GitHub under the PostgreSQL License. The project is designed for immediate production utility, with a robust CI matrix covering both vanilla PostgreSQL and mesh topologies.
For teams looking to integrate this into their existing stacks, the documentation and reference architectures at docs.pgedge.com/coldfront provide a clear roadmap. The inclusion of a docker-compose quickstart—which initializes PostgreSQL, Lakekeeper, and SeaweedFS—allows developers to test the full lifecycle of a tiered table in minutes.
As pgEdge continues to integrate ColdFront into their pgEdge Enterprise Postgres offering, they are also bundling it with their wider Agentic AI Toolkit, which includes MCP servers, vectorizers, and document loaders. This comprehensive approach signals that pgEdge is not just building a storage plugin, but a foundational layer for the next generation of AI-integrated enterprise software.
In a world where data is the most valuable asset an organization possesses, the ability to store it cheaply without losing the ability to govern, correct, and query it is a strategic imperative. With ColdFront, pgEdge has finally removed the compromise, ensuring that PostgreSQL can continue to scale alongside the most demanding workloads of the next decade.
