

The landscape of edge computing and artificial intelligence is undergoing a transformative shift. Historically, computer vision and natural language processing (NLP) existed as distinct silos. A camera could detect a "cat," and a chatbot could discuss "cats," but bridging the gap between a live visual feed and a reasoned, human-like narrative required massive computational overhead and cloud reliance.
This week, Raspberry Pi officially bridged that gap. In a specialized "Maker Monday" tutorial—extended into Tuesday following a UK Bank Holiday—Lucy Hattersley, Editor of the Raspberry Pi Official Magazine, unveiled a workflow that marries the hardware-accelerated Raspberry Pi AI Camera with the reasoning capabilities of Large Language Models (LLMs). This synthesis has birthed a new category of accessible technology: Vision-Language Models (VLMs) that operate with a focus on privacy, efficiency, and real-world utility.
Main Facts: The Convergence of Vision and Language
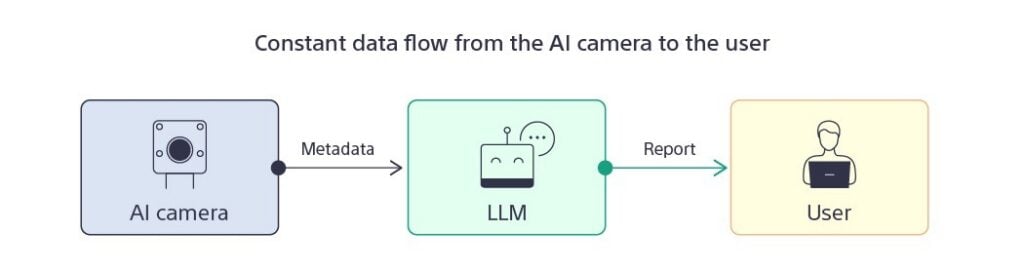
The core innovation presented by the Raspberry Pi Foundation lies in the transition from simple object detection to "contextual reasoning." By utilizing the Raspberry Pi AI Camera—which features the Sony IMX500 intelligent vision sensor—the system performs on-device AI inference. Instead of streaming high-bandwidth, privacy-sensitive video to a remote server, the camera processes the image locally and outputs only structured metadata.
The Metadata Bridge
This metadata—consisting of object labels, bounding box coordinates, and confidence scores—is then fed into an LLM (such as OpenAI’s GPT-4 or local equivalents). The LLM acts as the "brain," interpreting the raw data into natural language. For instance, where a traditional camera sees [Person: 0.92, Cat: 0.85], the integrated system reports: "A person is currently in the living room interacting with the cat."
Key Advantages of the VLM Approach
- Privacy and GDPR Compliance: Since no raw video leaves the device, the risk of data breaches involving sensitive imagery is virtually eliminated.
- Bandwidth Efficiency: Sending a few bytes of text metadata to the cloud is significantly cheaper and faster than streaming 1080p or 4K video.
- Natural Interaction: Users can query their environments using natural language rather than monitoring complex dashboards.
Chronology: From Hardware Setup to Intelligent Insight
Implementing a Vision-Language Model on a Raspberry Pi involves a structured sequence of hardware integration and software configuration. The following timeline outlines the deployment process for developers and makers.
Phase 1: Hardware Integration and Firmware
The process begins with the physical connection of the Raspberry Pi AI Camera to a Raspberry Pi 4 or 5. Unlike standard cameras, the IMX500 sensor requires specific runtime firmware to be uploaded to the sensor itself during the boot sequence. This ensures the onboard AI accelerator is ready to handle neural network workloads.

Developers must first ensure their operating system is current:
$ sudo apt update && sudo apt full-upgradeFollowing the update, the specific firmware for the IMX500 must be installed:
$ sudo apt install imx500-allPhase 2: Environment Configuration
To prevent library conflicts and manage dependencies, the project utilizes a Python virtual environment. This is a critical step for maintaining system stability while integrating third-party APIs like OpenAI.
$ python -m venv env
$ source env/bin/activate
$ pip install modlib openaiThe modlib (Application Module Library) acts as the intermediary, handling the data flow from the AI camera’s inference engine to the Python application.
Phase 3: The "Brain" Connection
The final chronological step involves cloning the project repository and configuring the API credentials. Users must integrate their OpenAI API key into the script (e.g., 01_aicam_to_llm.py). Once the script is executed, the camera begins its 30-second initialization—uploading the network firmware—before entering a continuous loop of detection and description.
Supporting Data: Technical Specifications and Performance
The efficacy of this system is rooted in the hardware-software synergy of the IMX500 sensor and the efficiency of the JSON metadata format.
The Sony IMX500 Sensor
The Raspberry Pi AI Camera is not a traditional image sensor; it is a dedicated AI processor. It handles the "heavy lifting" of object detection (inference) directly on the chip. This reduces the CPU load on the Raspberry Pi, allowing the microprocessor to focus on managing the LLM API calls and application logic.
Data Flow Analysis
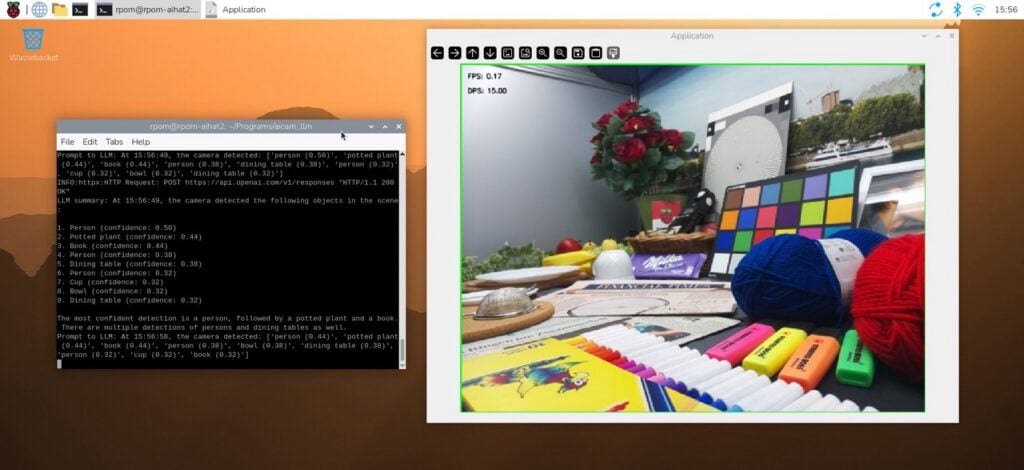
In a typical deployment, the camera generates a stream of inference results. A sample output might look like this:
- Timestamp: 16:33:29
- Detections:
- Person (Confidence: 0.44)
- Book (Confidence: 0.44)
- Potted Plant (Confidence: 0.38)
- Dining Table (Confidence: 0.38)
When this data is processed through an LLM with a prompt such as "Describe the scene based on these detections," the output is transformed into a coherent summary: "The camera suggests a setting likely involving people, reading materials, and dining or relaxation items."
Practical Applications: Three Key Use Cases
The versatility of the VLM approach is best demonstrated through its application in various sectors, from domestic security to industrial safety.
1. The Smart Home Observer
In a residential context, the system moves beyond simple motion alerts. By providing the LLM with context—"You have access to a smart camera in the living room"—the system can distinguish between routine activities and unusual events. It can report that the cat is on the sofa or that a package has been left by the door, providing a "friendly" text update rather than a jarring alarm.
2. Retail Shelf Monitoring
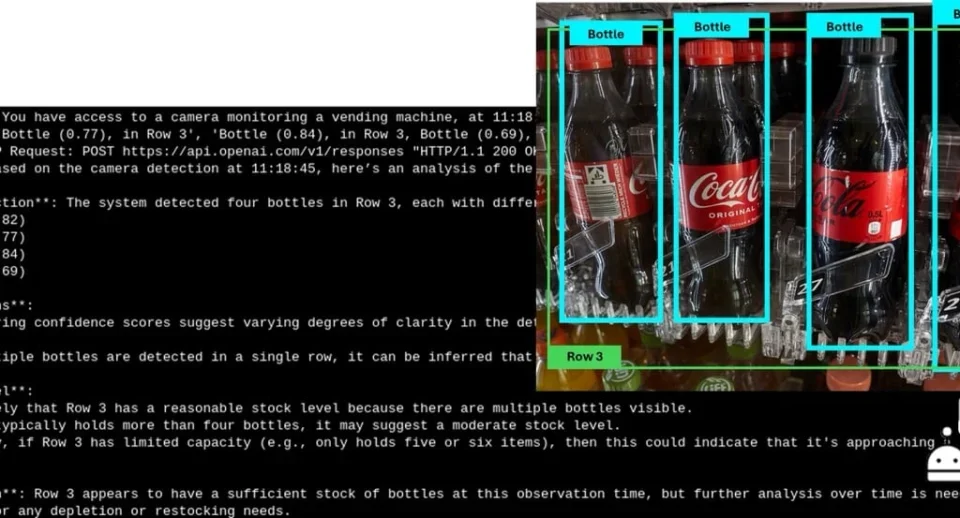
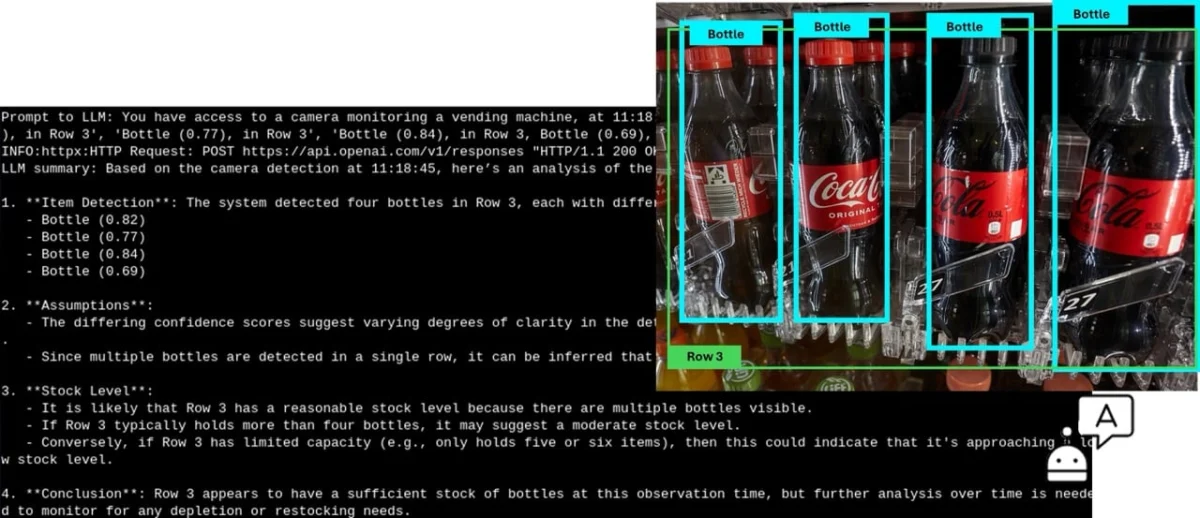
For businesses, the AI camera can be positioned to monitor vending machines or retail displays. By instructing the LLM to provide information on stock levels, a manager can receive reports such as: "Four soda bottles are left in row three—stock may need replenishing soon." This automates inventory management without requiring a human to constantly watch a video feed.
3. Factory Floor Safety (The Watcher)
In industrial environments, the system can be trained to detect Personal Protective Equipment (PPE). By matching "Person" detections with "High-Vis Jacket" detections, the LLM can generate immediate natural language alerts: "Warning: one worker is not wearing a high-vis jacket in the warehouse area." This provides a layer of safety oversight that is both autonomous and communicative.
Official Responses: The Maker Perspective
Lucy Hattersley, representing the Raspberry Pi Official Magazine, emphasized that this tutorial is designed to democratize complex AI. By providing a GitHub repository with modular code, the Foundation aims to empower users to write their own "prompts" for the physical world.
"Large language models offer new intuitive ways to interact with technology," Hattersley noted. She highlighted that the ability to adjust the system’s behavior by simply changing a text prompt (on line 23 of the provided code) represents a paradigm shift in how we program hardware. No longer do users need to be experts in computer vision mathematics; they simply need to be able to describe the task in English.
The Raspberry Pi Foundation’s move to support VLMs also reflects a broader commitment to "Edge AI," where intelligence is localized to the device. This aligns with the Foundation’s mission to provide high-performance, low-cost computing tools that respect user autonomy and privacy.
Implications: The Future of the "Sentient" Edge
The integration of Raspberry Pi’s AI Camera with LLMs has profound implications for the future of the Internet of Things (IoT) and artificial intelligence.
The End of the "Dumb" Sensor
We are entering an era where sensors are no longer "dumb" collectors of data but "articulate" observers. The ability for a $70 camera and a $60 computer to reason about their surroundings marks the end of the divide between high-end industrial AI and consumer-grade maker projects.

Ethical and Privacy Standards
By championing a metadata-only approach, Raspberry Pi is setting a standard for ethical AI. In an age of increasing surveillance concerns, the VLM model proves that we can have "smart" environments without sacrificing the visual privacy of the individuals within them. The camera "sees" to understand, but it does not "record" to intrude.
Accessibility in Development
Perhaps the most significant implication is the lowering of the barrier to entry. Prompt engineering is becoming the new "coding" for hardware. As LLMs become more efficient and capable of running locally on devices like the Raspberry Pi 5, the reliance on external APIs (like OpenAI) will diminish, leading to entirely self-contained, intelligent vision systems that can talk, reason, and assist in real-time.
In conclusion, the marriage of the Raspberry Pi AI Camera and Large Language Models is more than a technical curiosity; it is a blueprint for the next generation of ambient intelligence. Whether it is monitoring a shelf, guarding a factory, or simply keeping an eye on the family pet, the "Maker Monday" tutorial has shown that the future of AI is not just in the cloud—it is right at the edge, and it is more articulate than ever.