

In the rush to deploy enterprise-grade generative artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as the architecture of choice. By anchoring Large Language Models (LLMs) in proprietary databases, RAG promises to eliminate the hallucinations that plague raw models.
Yet, engineering teams worldwide are encountering a frustrating paradox: the vector database successfully retrieves the correct documents, similarity scores are exceptionally high, and yet the LLM still generates an incorrect, misleading, or completely fabricated response.
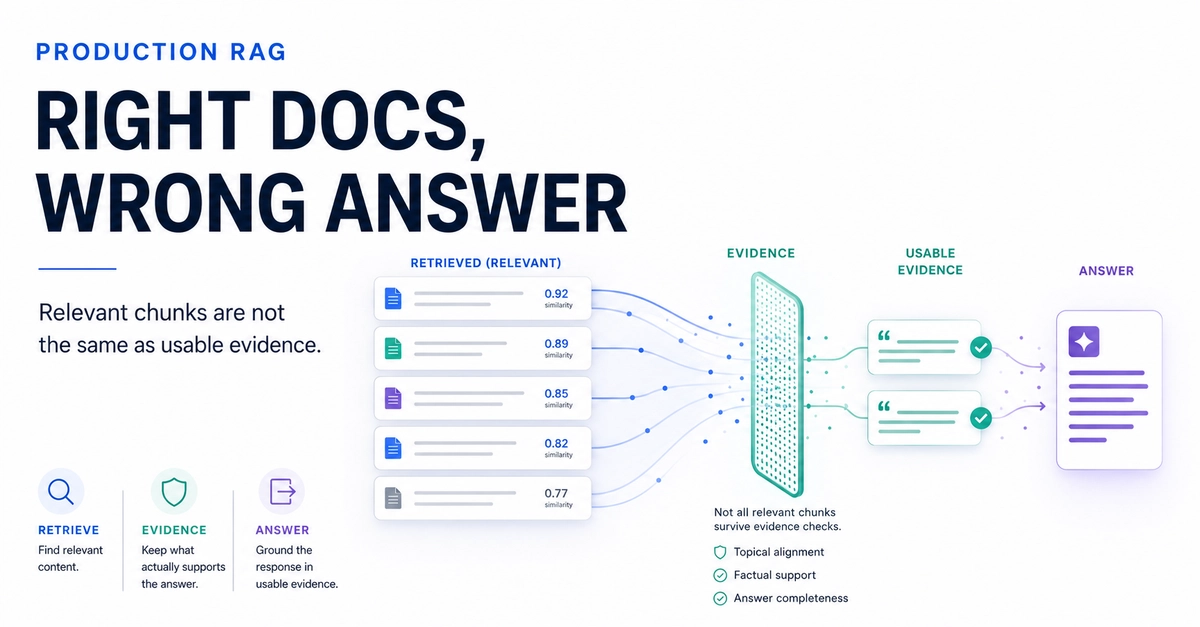
This failure mode is one of the most persistent and insidious challenges in production AI. While typical optimization efforts focus on improving search and retrieval, they fail to address the fundamental gap between semantic similarity and factual sufficiency.
1. Main Facts: The Paradox of High Similarity and Low Accuracy
The fundamental premise of RAG is simple: find documents relevant to a user’s query, append them to the LLM’s prompt as context, and instruct the model to answer based strictly on that context.
When a RAG system fails, the standard diagnostic assumption is that the retriever failed to locate the relevant information. Consequently, development teams invest heavily in upgrading their retrieval pipelines. They implement cross-encoder rerankers, increase the number of retrieved chunks (top-$k$), transition to hybrid search (combining dense vector embeddings with sparse BM25 keyword matching), or adopt more advanced embedding models.
However, in many production environments, these upgrades do not solve the root problem. The system’s retriever functions perfectly, delivering the exact document containing the target topic with high similarity scores. Yet, the output remains incorrect.
This issue stems from a conceptual misunderstanding: semantic similarity does not equal factual sufficiency.
+-----------------------------------------------------------------------+
| Traditional RAG Pipeline |
| |
| [Query] ---> [Vector Search] ---> [Top-K Chunks] ---> [LLM Gen] |
| | | |
| v v |
| "Is this topic "Highly similar |
| related?" content" |
+-----------------------------------------------------------------------+
VS
+-----------------------------------------------------------------------+
| Verified RAG Pipeline |
| |
| [Query] ---> [Vector Search] ---> [Evidence Check] -> [LLM Gen] |
| | |
| v |
| "Does this chunk |
| contain the actual |
| facts to answer?" |
+-----------------------------------------------------------------------+The Difference Between Relevance and Truth
Vector databases rely on mathematical proximity in a high-dimensional vector space. They excel at answering the question: "Is this chunk of text about the same general topic as the user’s query?"
They do not, however, answer the question: "Does this chunk contain the specific, granular facts required to logically support the correct answer?"
A retrieved document can share vocabulary, syntax, and subject matter with a query—yielding a near-perfect similarity score—while lacking the exact factual nugget required. When faced with this highly relevant but factually incomplete context, LLMs do not naturally stop and declare a lack of information. Instead, they leverage their inherent linguistic fluency to synthesize a highly plausible, beautifully formatted, and thoroughly cited incorrect answer.
This phenomenon is known as cosmetic grounding: the output looks like it is derived from the retrieved source text, but the actual logical connection is non-existent.
2. Chronology: The Evolution of RAG and the Emergence of the Sufficiency Gap
To understand how enterprise AI arrived at this bottleneck, it is useful to trace the evolution of RAG architectures over the past several years.
2022-2023: The Naive RAG Era
├── Basic vector embeddings (Cosine similarity)
└── Quick prototypes, but high rate of complete hallucinations
│
▼
2023-2024: Retrieval Optimization Era
├── Integration of cross-encoder rerankers & hybrid search (BM25 + dense)
└── Focus on "finding the needle in the haystack"
│
▼
Present: The Sufficiency Crisis
├── High recall achieved, but LLMs still generate incorrect answers
└── Shift toward verification, active critiquing, and self-RAGPhase 1: The Naive RAG Era (Late 2022 – Mid 2023)
Following the public release of ChatGPT, developers quickly realized that pre-trained LLMs lacked access to real-time or proprietary data. The first generation of RAG, often called "Naive RAG," was rapidly adopted. It relied on simple chunking strategies, basic vector embeddings, and standard cosine similarity calculations.
The primary failure mode during this era was retrieval failure. The vector search simply could not find the correct documents, leading to blatant hallucinations where the model relied on its pre-trained weights to make up answers.
Phase 2: The Retrieval Optimization Era (Late 2023 – Early 2024)
As Naive RAG proved too fragile for production, the industry entered an optimization phase. Engineers introduced sophisticated middleware to improve retrieval precision. Reranking models (such as Cohere Rerank or BGE-Reranker) were introduced to re-evaluate the top-100 retrieved chunks and bubble up the most relevant ones. Hybrid search combined keyword search with semantic search to catch specific product codes or names.
These techniques successfully solved the retrieval problem. The "needle in the haystack" could now be consistently found and placed into the LLM’s context window.
Phase 3: The Sufficiency Crisis (Present)
With the retrieval pipeline highly optimized, a new, more difficult failure mode emerged. Despite having the correct documents in the prompt, LLMs continued to generate incorrect answers.

Teams realized that even when the correct document is present, it might not contain the complete set of facts required to answer a specific question, or the LLM might struggle to synthesize information across multiple retrieved chunks. This has forced a shift in focus from retrieval optimization to context verification and reasoning.
3. Supporting Data: The Mechanics of Semantic Mismatch
The root of this issue lies in the mathematical design of vector embeddings. Embedding models map text into a vector space where distance represents semantic similarity. While highly effective for search, this mathematical representation does not capture logical relationships such as entailment, negation, or sufficiency.
The Math Behind the Failure
Consider an enterprise customer support bot for a telecommunications company. A user asks:
"Does the Premium Plan cover international roaming in Switzerland?"
The retriever searches the policy database and finds a document with a similarity score of 0.91 (extremely high):
[Retrieved Chunk]
"Our Premium Plan offers unparalleled global connectivity. Subscribers enjoy
unlimited high-speed data across 140+ countries, including comprehensive coverage
throughout the European Union, making it the premier choice for international travelers."Mathematically, this chunk is a perfect match. It contains the terms "Premium Plan," "international," "coverage," and "global connectivity."
Logically, however, the chunk is insufficient. Switzerland is not a member of the European Union. While the chunk is highly similar to the query, it does not contain the specific fact needed to answer the question.
If this chunk is passed directly to an LLM, the model will often hallucinate a "Yes" because Switzerland is geographically in Europe, and the retrieved text strongly implies broad European coverage.
Quantitative Industry Insights
Data from RAG evaluation frameworks (such as Ragas, TruLens, and Phoenix) highlights this systemic gap. In evaluations of production RAG pipelines across financial services and legal tech, researchers have categorized RAG failures into distinct buckets:
| Failure Category | Description | Prevalence in Production |
|---|---|---|
| Retrieval Failure | The correct document was not in the top-$k$ retrieved chunks. | ~30% (in optimized pipelines) |
| Sufficiency Failure | The correct document was retrieved, but it lacked the specific facts needed to answer. | ~45% |
| Synthesis/Reasoning Failure | The correct facts were present in the context, but the LLM failed to extract or connect them. | ~25% |
This data indicates that nearly half of all production RAG failures occur after the retrieval system has successfully done its job. Upgrading the vector database or embedding model cannot resolve these sufficiency and synthesis failures.
4. Academic Frameworks and Expert Perspectives
The academic community and leading AI research labs have documented this issue under various technical frameworks.
The "Lost in the Middle" Phenomenon
In a landmark 2023 study titled "Lost in the Middle: How Language Models Use Long Contexts," researchers from Stanford University, UC Berkeley, and other institutions demonstrated that LLMs are highly sensitive to where information is located within their input context.
LLM Retrieval Accuracy vs. Information Position
100% +---------------------------------------------------+
| / |
| / |
80% | / |
| / |
| / |
60% | / |
| / |
| / |
40% | / |
| / |
| _________________________/ |
0% +---------------------------------------------------+
Beginning Middle End
Position of InformationThe study revealed that language models are excellent at retrieving information at the very beginning or the very end of their input context, but their accuracy drops significantly when the crucial information is buried in the middle.
This means that even if a high-performing retriever places the correct document in a top-10 list, the LLM may still fail to utilize it if it is positioned in the middle of the prompt.
Active and Corrective RAG (CRAG)
To address this issue, researchers have proposed architectures like Corrective Retrieval-Augmented Generation (CRAG) and Self-RAG.
In a CRAG framework, a lightweight evaluator model is introduced to assess the quality of the retrieved documents for a given query. The evaluator classifies the retrieved documents into three states:
- Correct: The retrieved context contains the necessary facts.
- Incorrect: The retrieved context is irrelevant.
- Ambiguous: The retrieved context is relevant but may not be sufficient.
If the evaluator returns "Ambiguous" or "Incorrect," the system bypasses the standard generation step, either triggering a web search to fill the gaps or prompting the model to gracefully decline to answer.

5. The Paradigm Shift: From Retrieval to Verification
Solving the sufficiency problem requires a fundamental shift in how developers design RAG architectures. Engineering teams must stop treating retrieved documents as absolute truth and start treating them as unverified candidate material that must pass an explicit evidence check before generation.
Verification Pipeline Architecture
+-------------------------+
| User Query |
+------------+------------+
|
v
+-------------------------+
| Vector Retrieval |
+------------+------------+
|
v
+-------------------------+
| Reranked Docs |
+------------+------------+
|
v
+-----------------------------------+
| Evidence Verification Gate (LLM) |
+-----------------+-----------------+
|
Does the context contain the
specific facts needed?
/
YES NO
/
v v
+---------------------------+ +---------------------------+
| Generate Answer with | | Abstain / Fallback |
| Strict Grounding | | "I lack sufficient info" |
+---------------------------+ +---------------------------+To build a reliable RAG system, developers should implement a multi-stage verification pipeline.
Step 1: Implement an Explicit Sufficiency Assessment
Before the LLM attempts to write an answer, a dedicated, highly structured prompt (or a smaller, fine-tuned model) should evaluate the retrieved context. This step asks a binary question: "Does the provided context contain the specific facts required to answer the query?"
# Conceptual implementation of a Sufficiency Check Gate
def verify_context_sufficiency(query: str, retrieved_chunks: list) -> bool:
verification_prompt = f"""
You are an expert fact-checker. Analyze the following Query and the provided Context.
Your task is to determine if the Context contains the explicit facts required to fully and accurately answer the Query.
Query: query
Context: chr(10).join(retrieved_chunks)
Respond with JSON format only:
"sufficient": true/false,
"missing_facts": "description of facts that are missing, if any",
"confidence_score": 0.0 to 1.0
"""
response = call_llm(verification_prompt)
return response["sufficient"]Step 2: Establish Strict Abstention Rules
If the sufficiency check returns false, the system must not attempt to answer. Instead, it should trigger a managed fallback mechanism. This could mean returning a standardized response: "I apologize, but our internal documentation does not contain the specific information required to answer your question."
In enterprise applications, a clean refusal is always preferable to a highly convincing hallucination.
Step 3: Natural Language Inference (NLI) Post-Generation
Even if the context is sufficient, the generator LLM may still introduce errors during synthesis. To prevent this, developers can run a final Natural Language Inference (NLI) check.
An NLI model compares the generated answer against the retrieved context to ensure that every claim in the answer is logically entailed by the source text. If the model identifies an ungrounded claim, the answer is flagged and blocked before reaching the user.
6. Business and Technical Implications for Enterprise AI
As organizations transition from proof-of-concept AI tools to production deployments, the focus is shifting from simple features to reliability, safety, and auditability.
Production Trade-offs
Standard RAG Verified RAG
├─ Low Latency (1-2s) ├─ Moderate Latency (3-5s)
├─ Lower API Costs ├─ Higher Token Usage (Verification Step)
└─ High Risk of Hallucinations └─ Near-Zero Hallucinations (Production Ready)Risk Mitigation in Regulated Industries
For sectors such as healthcare, finance, and legal services, the cost of an incorrect AI-generated answer is exceptionally high. An AI assistant that provides incorrect medical advice or misinterprets a compliance regulation introduces severe liability risks.
Implementing verification gates allows organizations to enforce strict safety boundaries. It transforms AI assistants from unpredictable systems into deterministic, auditable software tools.
The True Cost of Verification
Adding verification and NLI steps to a RAG pipeline introduces a clear engineering trade-off: latency and cost vs. accuracy.
- Latency: Running multiple LLM calls (one for sufficiency verification, one for generation, and one for NLI) increases the time-to-first-token for the end-user.
- Cost: Additional reasoning steps increase the token count per query, raising API usage costs.
To optimize this process, engineering teams are increasingly using a tiered model approach. They employ smaller, faster, and cheaper models (such as fine-tuned 8B parameter models) to handle the initial sufficiency and NLI checks, reserving larger, more capable models (such as GPT-4o or Claude 3.5 Sonnet) for the final answer synthesis.
The Path Forward: Agentic RAG
The industry is moving toward Agentic RAG architectures. Rather than executing a single, linear pass (Retrieve -> Generate), agentic systems can iterate.
If a verification gate determines that retrieved context is insufficient, the agent can reformulate the search query, query a different database, or ask the user clarifying questions to obtain the missing information.
Ultimately, the transition from basic search-and-retrieval to rigorous evidence verification represents the next major milestone in enterprise AI. By recognizing that similarity is not the same as truth, developers can build RAG systems that are genuinely dependable in production.
