Beyond the Chatbot: How ‘Deep Agents’ and Operational Databases Are Redefining Enterprise Automation
In the evolving landscape of enterprise artificial intelligence, a quiet shift is occurring. Organizations are moving past simple, single-turn chatbot interfaces—which often suffer from limited context windows and a lack of state awareness—toward stateful, multi-step autonomous entities known as "Deep Agents."
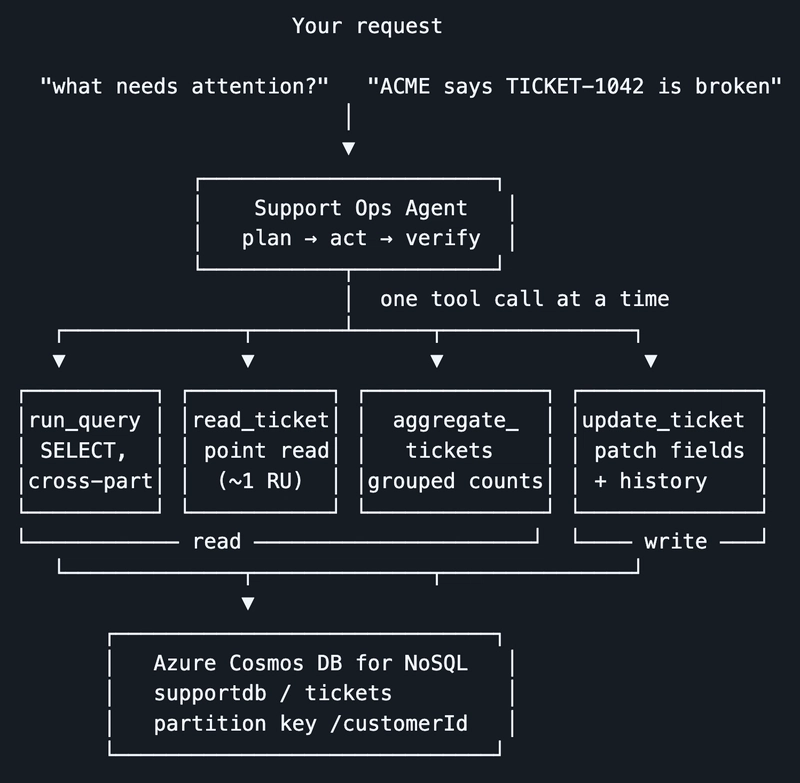
Recently, Microsoft showcased a breakthrough implementation of this paradigm: an agentic harness built on LangGraph designed to interface directly with live operational data in Azure Cosmos DB. This implementation, demonstrated via a sample "Support Ops Agent" application, reveals how modern AI can plan, act, and verify operations directly within a high-throughput NoSQL database. By executing complex workflows directly against a primary transactional store, this architecture bypasses the need for expensive, sync-heavy secondary indexes, pointing to a future where databases and autonomous AI are natively intertwined.
1. Main Facts: The Architecture of Deep Agents
At the core of this technological development is the transition from "passive" retrieval-augmented generation (RAG) to "active" agentic reasoning. Traditional LLM-based applications operate in a linear fashion: they receive a user prompt, retrieve relevant context, make a single call to a foundation model, and return a static response.
Deep Agents, by contrast, utilize LangGraph, an extension of the LangChain ecosystem designed for building stateful, multi-actor applications. This framework allows developers to model agent behavior as a cyclic graph. Instead of guessing the correct answer in one go, the agent establishes a plan, executes a series of tool calls, observes the outcomes, updates its internal state, and adapts its next steps dynamically.
+-----------------------------------+
| User Request |
+-----------------+-----------------+
|
v
+-----------------+-----------------+
| Support Ops Agent |
| (State, Todo List, Instructions) |
+--------+-----------------+--------+
| ^
Plan & Act | | Observe & Verify
v |
+--------+-----------------+--------+
| Tools |
| (Query, Point-Read, Patch, etc.) |
+-----------------+-----------------+
|
v
+-----------------+-----------------+
| Azure Cosmos DB |
| (Support Ticket Store) |
+-----------------------------------+Key Capabilities of the Deep Agent Harness
- On-Demand Skill Loading: Rather than bloating the LLM’s system prompt with every possible instruction and schema, the harness dynamically loads specific "how-to" guides or tool descriptions only when the active task requires them. This keeps the immediate context window clean and reduces token processing costs.
- Context Offloading: When tool outputs are excessively large (such as a query returning dozens of raw JSON documents), the harness offloads the bulk data from the primary LLM context, passing only synthesized summaries or references to subsequent steps.
- Human-in-the-Loop Validation: For sensitive operational changes—such as updating customer records or modifying billing states—the harness can pause execution, save its state, and await explicit human authorization before applying changes to the database.
- Zero Side-Indexes: By working directly with Azure Cosmos DB through its standard SDK, the agent interacts with live operational data in real-time. This eliminates the latency and synchronization issues inherent in pipelines that replicate transactional data to separate search or vector databases.
2. Chronology of an Agentic Session: How the Agent Thinks and Acts
To understand how a Deep Agent differs from a standard database script or a basic chatbot, we can examine its step-by-step workflow across three common enterprise scenarios: queue triage, targeted ticket resolution, and systemic incident detection.
Scenario A: The Morning Triage Loop
When a support manager logs in and asks, "I just got in, what should I look at first?", a standard database query cannot provide an adequate answer because "importance" is subjective and contextual. The Deep Agent resolves this through a multi-step loop:
- Analyze and Formulate: The agent interprets "what should I look at first" as a question of operational risk. It defines risk as active tickets of high priority (P1 or P2) that have remained idle for several days.
- Query Generation: The agent formulates and executes a read-only SQL query against the Cosmos DB container to fetch stale, open, or in-progress tickets.
- Aggregate Queue Context: To provide broader context, the agent simultaneously triggers a series of grouped count operations to determine the total volume of open tickets and identify current bottlenecks.
- Synthesize and Recommend: Instead of dumping raw data, the agent evaluates the query results, ranks them by urgency, drafts a brief justification for each recommendation, and delivers an actionable briefing to the user.
Scenario B: Target Resolution and the Verification Loop
When instructed to act on a specific ticket—such as, "GLOBEX is unhappy about TICKET-1050, can you pick it up and move it forward?"—the agent executes a strict read-write-verify sequence:
- Point Read: The agent initiates a highly efficient point read using the ticket ID and the partition key (
/customerIdset toGLOBEX). - Contextual Search: Before modifying the ticket, the agent queries other active tickets for GLOBEX and scans the broader queue for similar symptoms (e.g., authentication issues) to see if the problem is systemic.
- In-Place Patching: The agent executes an atomic patch operation on the target item in Cosmos DB, updating its status to
in-progress, assigning an engineer, adding tags, and appending a detailed entry to the item’s internal history array. - Verification Read: Critically, the agent does not assume the write succeeded based on an API response. It performs a final read-back of the updated document, comparing the live database state against its target state before reporting success to the user.
Scenario C: Uncovering Systemic Incidents
When given a vague warning like, "Logins feel shaky this week, dig in and flag anything related," the agent acts as an investigator:
- Initial Domain Search: The agent queries active tickets categorized under the
loginarea. - Semantic Expansion: Recognizing that users describe issues differently, the agent constructs a secondary text-search query. It scans tickets outside the login category for keywords like "authentication," "sign in," or "MFA."
- Correlate and Pattern-Match: The agent processes the combined results, grouping them by customer and creation date. It flags a surge in login-related failures across multiple customers occurring within the same 48-hour window.
- Propose Corrective Action: The agent presents its findings, identifies a misfiled critical ticket, and asks the user for permission to tag all seven related tickets with a unified incident identifier (
known-issue:login-surge).
3. Supporting Data and Technical Deep-Dive
The integration of autonomous agents with operational databases requires careful architectural design to control costs, maintain performance, and handle SDK-specific constraints. The Deep Agents sample application highlights several key database design patterns optimized for Azure Cosmos DB.
Point Reads vs. Cross-Partition Queries
Azure Cosmos DB charges for operations using Request Units (RUs). Designing efficient queries is essential for keeping operational costs predictable:
| Database Operation | Target Scope | RU Efficiency | Primary Use Case |
|---|---|---|---|
| Point Read | Single Partition (/customerId + id) |
Extremely High (~1 RU) | Fetching or updating a specific ticket once its ID and customer are known. |
| Scoped Query | Single Partition (/customerId filter) |
High | Reviewing the ticket history or current active issues for a single client. |
| Cross-Partition Query | Queue-wide (No partition filter) | Variable (proportional to dataset size) | Broad queue triage, identifying systemic incidents, or calculating system-wide metrics. |
To minimize RU consumption during cross-partition queries, the agent’s tools are explicitly instructed to project only the minimal required fields (such as id, priority, status, and updatedAt) rather than returning entire, bloated documents.
Atomic Updates via the Patch API
Rather than downloading a document, modifying it in memory, and replacing the entire item—which risks write conflicts and consumes unnecessary bandwidth—the agent utilizes Cosmos DB’s native Patch API.

The Python code snippet below demonstrates how the agent constructs atomic patch operations, ensuring that metadata like updatedAt is updated and audit logs are appended in a single round-trip:
# The agent constructs a localized patch array rather than replacing the entire document
ops = ["op": "set", "path": f"/k", "value": v for k, v in fields.items()]
ops.append("op": "set", "path": "/updatedAt", "value": now)
if history_note:
# Appends directly to the end of the history array without retrieving it first
ops.append(
"op": "add",
"path": "/history/-",
"value": "at": now, "by": history_by, "note": history_note,
)
# Execute the atomic patch against the target item
_get_container().patch_item(
item=ticket_id,
partition_key=customer_id,
patch_operations=ops,
)Overcoming SDK Limitations: Client-Side Aggregations
A notable technical challenge in distributed databases is performing aggregations across multiple partitions. While Azure Cosmos DB’s backend engine supports cross-partition queries, the azure-cosmos Python SDK restricts cross-partition GROUP BY operations, returning an error:
"Cross partition query only supports 'VALUE' for aggregates."
To resolve this limitation, the Deep Agents framework implements a hybrid aggregation model:
- The
aggregate_ticketstool projects the target grouping field (e.g.,statusorassignee) across all partitions. - The raw, lightweight stream of values is returned to the agent’s environment.
- The tool aggregates and counts these values in-memory using Python.
- The final consolidated summary is then presented to the LLM.
This approach keeps network payloads small while working around SDK-specific limitations.
4. Industry Context: The Shift in Enterprise Data Patterns
The emergence of frameworks like LangGraph and Deep Agents highlights a broader shift in how enterprises approach AI-driven automation.
TRADITIONAL PIPELINE (High Latency, High Complexity)
+-------------+ ETL +------------+ Sync +-------------+
| Operational | =========> | Vector DB | =========> | AI Chatbot |
| Database | | / Search | | (Read-Only) |
+-------------+ +------------+ +-------------+
AGENTIC DIRECT-ACCESS PIPELINE (Real-Time, Low Complexity)
+-------------+ Direct SDK Read/Write +-------------+
| Operational | <=====================================> | Deep Agent |
| Database | (Point Reads & Patches) | (Stateful) |
+-------------+ +-------------+For the past several years, the standard approach to generative AI involved building complex, asynchronous pipelines. Data was extracted from operational databases, transformed, loaded into specialized vector databases, and made available to read-only chatbots.
While this architecture works well for static knowledge bases, it is less suited for dynamic, action-oriented workflows like customer support, inventory management, or order fulfillment. For these use cases, enterprise leaders face several challenges:
- Data Stale-ness: ETL pipelines introduce sync lag, meaning an agent might make decisions based on outdated information.
- Architectural Overhead: Managing separate transactional and search databases increases operational complexity and licensing costs.
- Lack of Write Capabilities: Traditional RAG systems are read-only. Empowering an AI to solve problems requires giving it a secure, traceable way to write changes back to the system of record.
By utilizing standard database SDKs, Deep Agents can query and update transactional systems in real time. This architecture ensures that security, partitioning, and indexing rules configured at the database level are automatically inherited by the AI agent.
5. Implications: The Future of Database Design and Human Labor
As deep, stateful agents become more common in enterprise environments, their adoption will likely drive significant shifts in both database engineering and workplace dynamics.
Evolution of Database Features for AI Agents
To better support autonomous agents, database engines may evolve to include native features tailored for non-human users:
- Agent-Specific Access Policies: Traditional role-based access control (RBAC) may expand to include "agentic reasoning boundaries," restricting LLMs to specific execution paths and limiting the number of expensive queries they can run.
- Audit-Trail Automation: If databases are routinely updated by AI agents, native, tamper-proof audit trails will become critical. Features like automatically appending agent IDs and prompt hashes to transaction logs will help track the context behind automated decisions.
- Hybrid Query Engines: NoSQL engines may continue to optimize for hybrid workloads, balancing traditional point reads with vector-based semantic searches in a single query path.
Redefining the Support and Operations Landscape
In customer-facing operations, the integration of Deep Agents will shift the focus of human staff from routine tasks to higher-value work:
- From Data Entry to Oversight: Instead of manually updating ticket statuses, assigning owners, and writing summaries, human operators will act as supervisors. They will monitor the agent’s work, step in to handle complex exceptions, and approve high-impact actions through human-in-the-loop gates.
- Proactive System Maintenance: Armed with agents that can analyze the entire queue for systemic issues, support teams can shift from reactive troubleshooting to proactive incident management, resolving underlying software bugs before they trigger a flood of individual customer complaints.
- Accelerated Onboarding: Because the agent’s operational skills and business rules are stored as modular code blocks and dynamic prompts, updating organizational workflows simply requires updating the agent’s skills—instantly aligning the entire automated system with new company policies.
Ultimately, the combination of stateful frameworks like LangGraph and high-performance databases like Azure Cosmos DB demonstrates that AI’s role in the enterprise is shifting. AI is moving from a passive search assistant to an active partner capable of planning, executing, and verifying complex tasks directly within the systems that run the business.