Elevating the Soundtrack of Life: Spotify’s Breakthrough in Reinforcement Learning for Music Personalization
In the modern digital landscape, streaming services act as the gatekeepers of culture. For Spotify, the world’s most popular audio streaming subscription service, the challenge of personalization is not merely a technical hurdle—it is the core of the user experience. Spotify’s recommendation engines must curate ordered sets of tracks that perfectly align with a user’s shifting mood, intent, and environment.
To refine these complex, sequential decision-making processes, a team of Spotify engineers—Surya Kanoria, Joseph Cauteruccio, Federico Tomasi, Kamil Ciosek, Matteo Rinaldi, and Zhenwen Dai—has successfully deployed Reinforcement Learning (RL) powered by the TensorFlow and TF-Agents ecosystems. By creating a robust, offline simulated environment, the team has effectively bridged the gap between theoretical machine learning and real-world listener satisfaction.
The Core Challenge: Sequential Decision Making
At its heart, music consumption is inherently sequential. A user does not simply listen to a single track; they engage in a "session" defined by a series of choices, skips, and repeat plays. Traditional recommendation systems often treat these interactions as isolated events or static "slates." However, true personalization requires understanding the state of the listener as it evolves throughout a session.

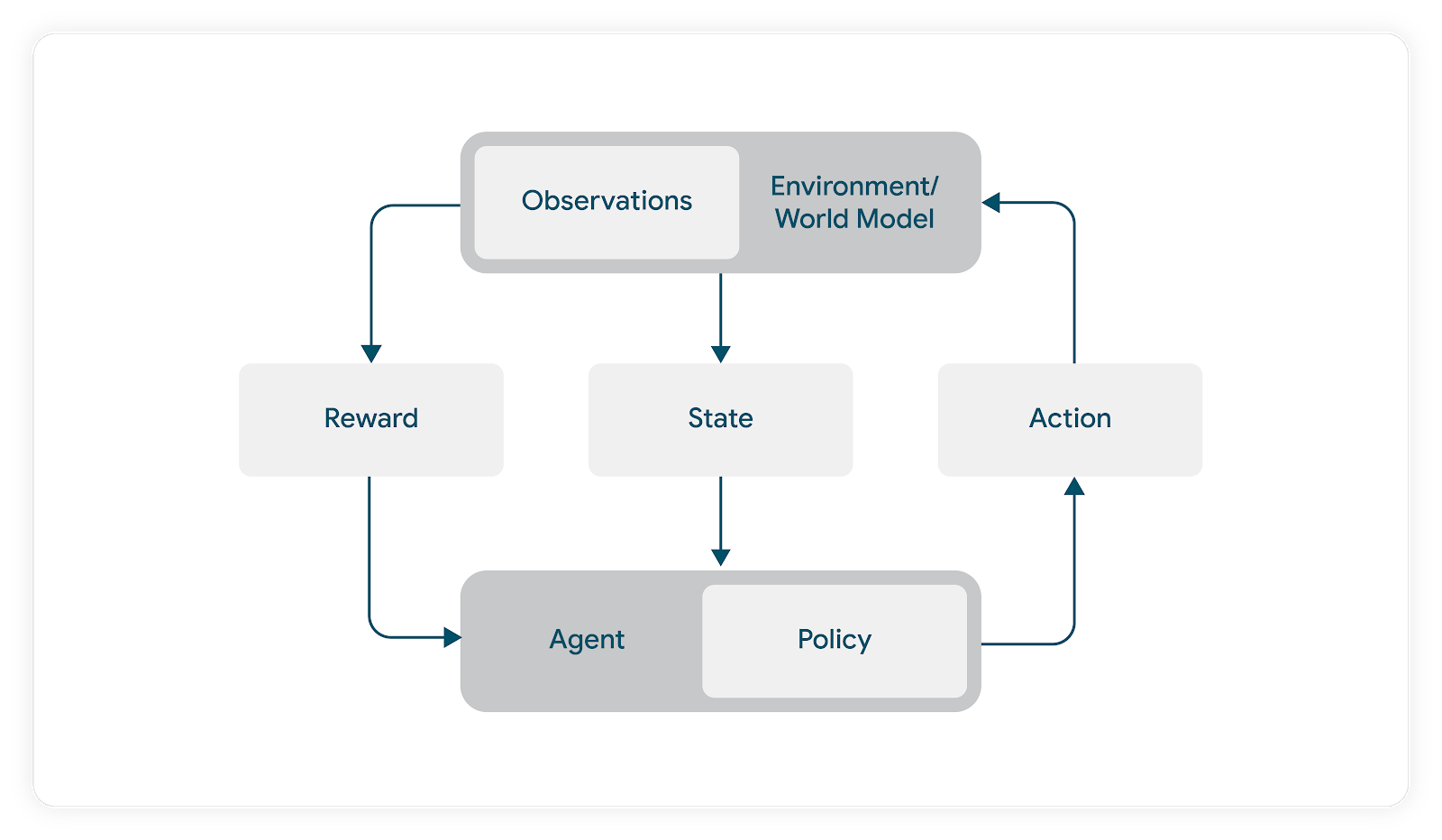
Reinforcement Learning provides a framework for agents to learn optimal policies by interacting with an environment, receiving feedback in the form of rewards. For Spotify, the "agent" is the recommendation algorithm, and the "reward" is the positive user response to a suggested track. The primary barrier to implementing RL in production is the "exploration problem": training an agent in the real world often involves exposing users to suboptimal recommendations, which could diminish the quality of their listening experience. To solve this, the team at Spotify needed a sandbox—a high-fidelity simulator that could mimic user behavior without compromising the service for actual listeners.
A Chronology of Innovation
The journey from concept to deployment required a deliberate, multi-phased approach, relying heavily on the TensorFlow ecosystem for scalability and efficiency.
Phase 1: Choosing the Foundation
Early in their research, the Spotify team recognized that their existing production infrastructure—built heavily on TensorFlow, TFX, and TensorFlow Serving—offered a massive advantage. By adopting TF-Agents as their primary RL library, they ensured that their experimental models would be inherently compatible with their production pipelines, drastically reducing the time required for future deployment.

Phase 2: Architecting the Simulator
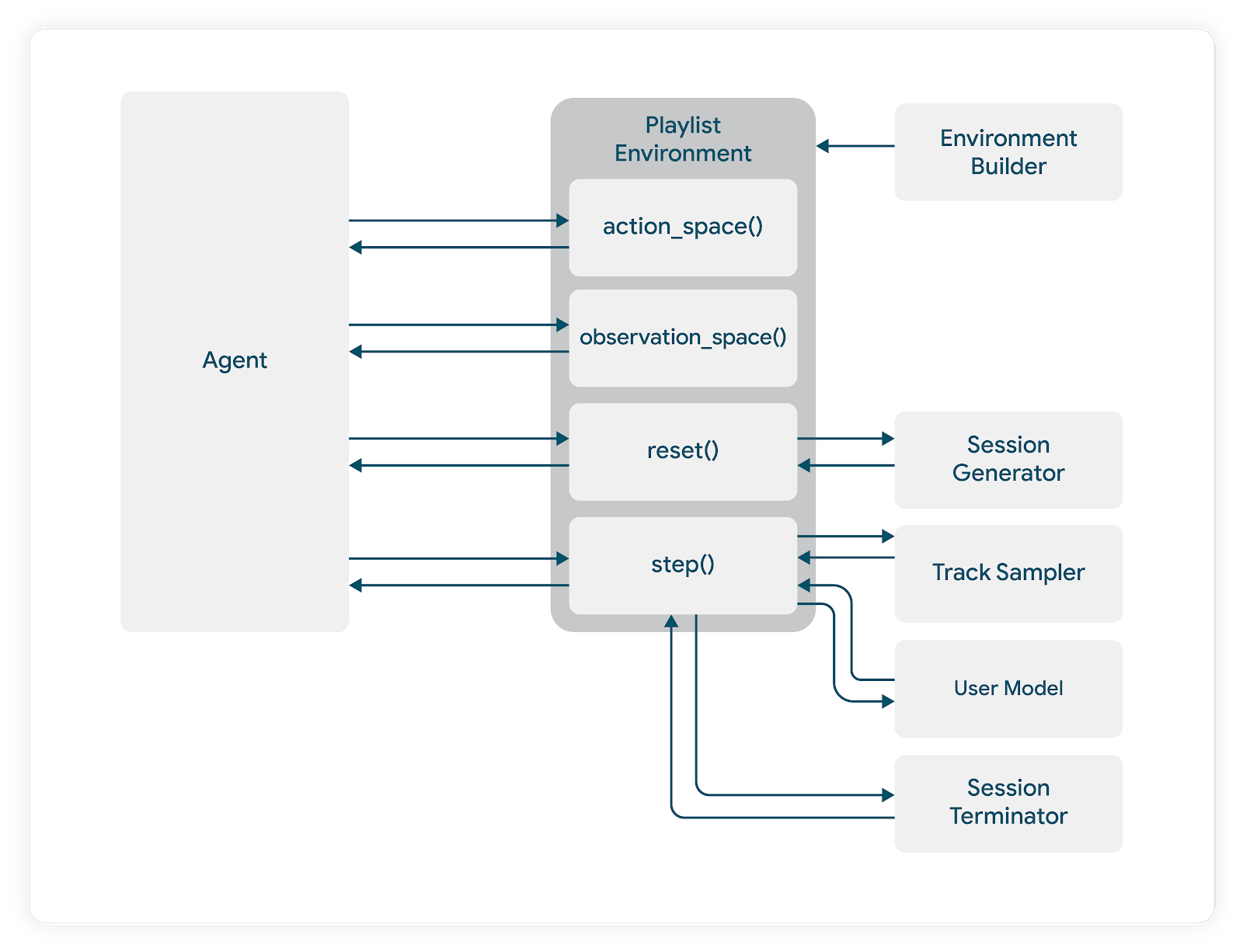
The team’s most significant engineering milestone was the development of a custom, offline Spotify simulator. Utilizing TF-Agents’ Environment primitives, they built a modular system capable of:
- User Modeling: Using Keras to create a predictive model of how a user would react to specific tracks.
- Track Sampling: Logic that translates the Agent’s abstract actions into concrete, high-quality music recommendations.
- Episode Management: A system that tracks session termination, allowing the agent to learn from sequences that mimic the statistical reality of user behavior (e.g., modeling the point at which a user is statistically likely to abandon a session).
Phase 3: The Birth of the "Action-Head DQN"
Standard Reinforcement Learning models often struggle with the combinatorial complexity of choosing an ordered list of items from a massive catalog. The team addressed this by developing a specialized variant of a Deep Q-Network called the Action-Head DQN (AH-DQN). Unlike traditional models that might output a single recommendation, the AH-DQN iteratively evaluates the state of the session, selects the item with the highest Q-value, adds it to the playlist, and repeats the process until the slate is filled.
Phase 4: Validation and Deployment
The team rigorously tested their models against both simulated and real-world data. By comparing the performance of various policies—including naive, heuristic, and model-driven approaches—they confirmed that their offline simulator was an accurate predictor of online user satisfaction. This "directional alignment" between simulated results and real-world outcomes was the final green light for broader application.
Supporting Data and Technical Architecture
The efficacy of this project rests on the modularity of the simulation environment. By strictly defining the AbstractEnvironment class, the team ensured that every component—from the user_model to the track_sampler—remained interchangeable and testable.
The Action-Head DQN represents a sophisticated shift in how RL is applied to slate generation. In typical slate recommendations, the system assumes a single point of interaction. Spotify’s approach acknowledges that users engage with multiple items in a single list. By iteratively selecting the next best item through the AH-DQN, the agent maintains a high degree of coherence throughout the listening session.
The correlation data provided by the Spotify team shows a clear, upward trend between the simulated performance metrics and the scaled online rewards. This validates the premise that model-based RL, when properly constrained, can serve as a reliable proxy for real-world user preferences.

Official Perspective: Spotify’s Engineering Philosophy
In their presentation at KDD 2023, the authors emphasized the collaborative nature of this breakthrough. The project was not the work of a single team but an iterative evolution involving contributions from various Spotify departments.
"We made the decision early on to leverage TensorFlow Agents," the team noted, "knowing that integrating our experiments with our production systems would be vastly more efficient down the line." This strategic decision to favor interoperability over bespoke, siloed solutions allowed them to iterate faster than would have been possible with a fragmented stack.
The acknowledgement of the TensorFlow Agents team highlights a growing trend in big-tech research: the reliance on open-source, community-supported frameworks to solve proprietary, large-scale problems. By utilizing the existing hooks provided by the TF-Agents library, Spotify was able to focus its R&D budget on the specific nuances of music consumption rather than reinventing the fundamental mathematics of reinforcement learning.

The Implications for the Future of Streaming
The success of this project has significant implications for the future of digital media.
Enhanced Personalization
By moving beyond static "if-then" heuristics to a dynamic, agent-based learning system, Spotify can better account for the "long tail" of user intent. The agent does not just suggest what is popular; it suggests what is appropriate for the current, unfolding context of the user’s session.
The Model-Based Advantage
The use of a model-based simulator sets a new industry standard for safety in RL. By training against a "digital twin" of their user base, companies can explore radical new recommendation strategies without risking the user experience. This "fail-safe" training environment encourages innovation by reducing the "cost" of failure.
Scaling RL to Production
Perhaps the most important implication is the demonstration that complex RL models can be successfully moved from a research environment to a massive production scale. The integration of Keras-based user models with TF-Agents demonstrates a clear path for other firms to follow.
A New Era of Discovery
As the AH-DQN and similar models are refined, the "discovery" aspect of music streaming will likely become more fluid. Users may find that their playlists feel more like a conversation with an intelligent curator rather than a rigid list of songs. For artists, this means that their music is more likely to reach the right listener at the exact moment they are most receptive, potentially increasing engagement and listener retention across the platform.
Conclusion
Spotify’s integration of Reinforcement Learning is more than just an optimization exercise; it is a fundamental shift in how streaming platforms understand their audience. By investing in a high-fidelity, offline simulation environment and utilizing the power of the TensorFlow ecosystem, the team has paved the way for a more responsive, personalized, and engaging future. As these models continue to evolve, they will undoubtedly serve as the backbone for the next generation of digital discovery, ensuring that the soundtrack of life remains perfectly synced with the listener.