Revolutionizing Temporal Data Engineering: How Temporian and TensorFlow Decision Forests Simplify Complex ML Workflows
In the rapidly evolving landscape of machine learning, the ability to process and interpret temporal data—information that evolves or holds significance only within a specific timeframe—has become a cornerstone of success. Whether it is predicting fluctuating market prices, monitoring erratic weather patterns, or analyzing the precise intervals between heartbeats for medical diagnostics, temporal data is everywhere. Yet, despite its ubiquity, preparing this data for machine learning models has historically been a fragmented, manual, and error-prone process.
To address these challenges, Google, in collaboration with the engineering team at Tryolabs, has introduced Temporian, a powerful new open-source Python library designed to streamline the preprocessing and feature engineering of temporal data. When paired with TensorFlow Decision Forests (TF-DF), developers now possess a robust, end-to-end pipeline for transforming raw transactional data into actionable predictive insights.

The Ubiquity and Complexity of Temporal Data
Temporal data is more than just a sequence of timestamps; it is a high-dimensional narrative of events. In fields like cybersecurity, the temporal patterns of network logs are critical for detecting malicious intrusions. In retail, the velocity of sales at specific intervals can dictate inventory strategy. The core challenge in these applications lies in the "non-synchronized" nature of the data.
Raw transactional data—such as individual retail purchases, sensor pings, or user clicks—rarely arrives in the clean, uniform intervals required by traditional machine learning algorithms. Instead, this data is often messy, irregular, and multi-indexed. Data scientists frequently spend the vast majority of their time "wrangling" this information into a usable format, performing complex joins, windowing, and resampling. Temporian aims to eliminate this bottleneck by providing a specialized framework for handling "event sets," allowing developers to perform sophisticated temporal operations with minimal code.

Chronology: Building a Forecasting Pipeline
The development of Temporian represents a shift in how engineers approach time-series problems. Historically, developers relied on standard data manipulation libraries like Pandas, which are excellent for general-purpose tasks but lack native optimizations for the specific temporal logic required in advanced ML pipelines.
Phase 1: Ingestion and Visualization
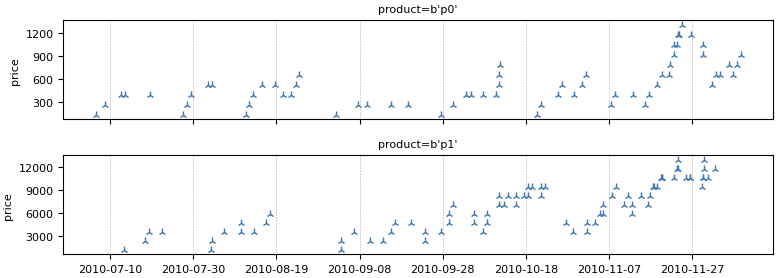
The first step in any ML workflow is understanding the data. Using Temporian, loading a CSV file of transactional sales is a seamless operation. By converting raw data into an EventSet—a specialized container for temporal data—users can instantly inspect and visualize features like transaction prices across thousands of individual clients and products.

Phase 2: Feature Engineering with Moving Windows
Once the data is ingested, the real value emerges through feature engineering. A common requirement in forecasting is the "moving sum"—calculating the total sales over a rolling period (e.g., the last seven days). Temporian allows for this with a single method call: moving_sum(). By applying this across indices—such as grouping by product or client—the library handles the complex alignment of time windows automatically, a task that would otherwise require nested loops or convoluted grouping operations.
Phase 3: Aggregation and Uniform Sampling
While transaction-level data is granular, ML models often require uniform sampling to find patterns. Temporian enables users to aggregate these irregular transactions into daily or weekly buckets. A critical feature here is the tick operator, which allows developers to define a custom sampling rate. This ensures that even when individual events occur at unpredictable times, the resulting data feed is consistent, allowing the model to learn from stable time intervals.

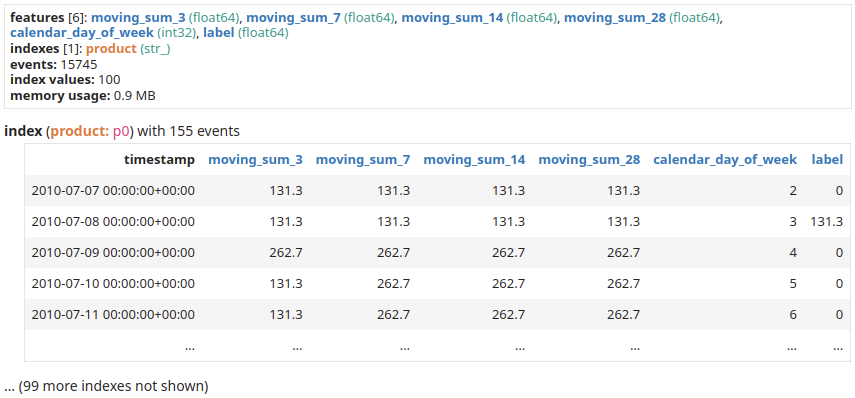
Supporting Data: From Raw Events to Model Inputs
To train a model effectively, one must transform raw data into a tabular format that machine learning algorithms can digest. Temporian facilitates this by allowing for the creation of multiple feature sets—such as moving sums of different window lengths (3, 7, 14, and 28 days)—and combining them with calendar-based features (e.g., day of the week).
The library’s glue function brings these disparate streams together, creating a unified dataset. This dataset is then converted directly into a TensorFlow Dataset. This transition is critical because it bridges the gap between raw, event-based logs and the structured input required by models like the Random Forest provided by TensorFlow Decision Forests.

In our specific case study of sales forecasting, the model training phase reveals the power of this approach. By analyzing the "variable importance" output from the trained Random Forest, we can see that the 28-day moving sum is the most significant predictor of future sales. This level of insight would be difficult to extract if the preprocessing had been done in a less specialized environment.
Official Perspective: Collaboration Between Google and Tryolabs
The development of Temporian is a result of a deep partnership between Google’s machine learning engineers and the team at Tryolabs. According to the contributors—including Mathieu Guillame-Bert, Richard Stotz, and Ian Spektor—the project was born out of a shared frustration with the "re-inventing the wheel" cycle that permeates temporal data science projects.

By open-sourcing the library, the collaborators intend to standardize how temporal data is processed across the industry. The primary design goal was to keep the API intuitive for those already familiar with Python data structures while hiding the extreme complexity of temporal algebra and time-alignment under the hood. As noted in the project’s documentation, the library is not merely a helper tool but a foundation upon which future anomaly detection, fraud detection, and predictive maintenance systems can be built.
Implications: A New Standard for Temporal ML
The implications of this technology are significant for both enterprise and research applications.
1. Reduced Development Time
By abstracting away the manual labor of data alignment, teams can move from raw data to a deployed model in a fraction of the time. The code snippets required for complex windowing operations are reduced from dozens of lines to just one or two, significantly lowering the risk of logical errors.
2. Enhanced Model Performance
Machine learning models are only as good as their input features. Because Temporian makes it trivial to experiment with different temporal windows, feature engineering becomes an iterative process. Engineers can test dozens of windowing strategies—such as comparing 3-day versus 28-day trends—without re-writing their entire data pipeline.

3. Scalability
Temporian is designed to handle large-scale event data, which is essential for modern business applications where logs are generated by millions of users simultaneously. Its ability to work with multi-indexed data means that businesses can maintain high-fidelity models for individual customers or products without needing to sacrifice computational efficiency.
4. Integration with the TensorFlow Ecosystem
Perhaps the most powerful aspect of this development is the seamless bridge to TensorFlow Decision Forests. By ensuring that the final output of the preprocessing stage is a native TensorFlow Dataset, the library ensures that users can leverage the full power of Google’s ML ecosystem, including model monitoring, deployment, and performance tuning tools.

Conclusion: The Path Forward
The integration of Temporian and TensorFlow Decision Forests represents a significant milestone in democratizing advanced temporal data analysis. As machine learning continues to move from the research lab to the operational front lines of retail, finance, and infrastructure, the tools we use to process time-dependent data must become as sophisticated as the models themselves.
For those looking to adopt these tools, the path forward is clear: start by identifying the temporal events in your current datasets that are currently being underutilized. Whether you are dealing with sparse event logs or high-frequency transactional data, the combination of Temporian’s intuitive feature engineering and the predictive power of Random Forests offers a robust, scalable solution for the next generation of intelligent applications.
As the open-source community continues to contribute to the Temporian ecosystem, we can expect to see further optimizations and pre-built operators for more complex domains, cementing its role as an essential component in the modern data scientist’s toolkit. With the complexities of time-alignment managed, engineers are now free to focus on what matters most: building models that don’t just predict the future, but help us understand the events that shape it.