Resilience at Scale: AWS Unveils the Next Generation of Resilience Hub
In the complex landscape of modern cloud architecture, "availability" is often the most pursued yet elusive metric. As enterprises scale their operations across hundreds of applications, maintaining a consistent standard for reliability has become a significant operational bottleneck. Today, Amazon Web Services (AWS) addressed this challenge head-on by announcing the next generation of AWS Resilience Hub, a comprehensive evolution of its flagship service designed to standardize, measure, and enforce resilience goals across an entire enterprise.
This update represents more than a minor feature release; it is a fundamental shift in how Site Reliability Engineers (SREs) and development teams approach system health. By integrating generative AI-powered failure mode analysis, modular policy management, and deep organizational visibility, AWS is providing a structured framework to ensure that reliability is no longer an afterthought, but a baked-in component of the application lifecycle.
Main Facts: A Paradigm Shift in Cloud Reliability
The core value proposition of the new AWS Resilience Hub lies in its ability to bridge the gap between abstract business requirements and technical implementation. Historically, teams within the same organization often operated in silos—using disparate tools, setting conflicting recovery time objectives (RTO), and struggling to prove compliance to stakeholders.

The next generation of the service introduces five critical pillars:
- A Unified Application Model: This replaces legacy configurations with a more flexible structure, allowing teams to group related microservices into "Systems" that mirror real-world business functions.
- Automated Dependency Discovery: By analyzing VPC query logs, the service now automatically maps the hidden relationships between resources, ensuring that "ghost dependencies" do not lead to unexpected outages.
- Generative AI-Powered Failure Mode Analysis: Utilizing advanced machine learning models, the service now identifies potential failure points and provides intelligent, actionable recommendations to mitigate them.
- Modular Resilience Policies: Organizations can now define "Policy Templates"—such as a high-availability policy for financial transaction systems—and apply them consistently across different teams and accounts.
- Organization-Wide Reporting: Through native integration with AWS Organizations, administrators can achieve a birds-eye view of their entire infrastructure’s resilience posture without needing to pivot between individual account consoles.
Chronology: The Evolution of AWS Resilience Hub
To understand the magnitude of this release, one must look at the progression of AWS’s reliability offerings.
- Early Stages: AWS initially focused on infrastructure-level availability, providing tools like Auto Scaling and Multi-AZ deployments. However, these were often disconnected from the application’s actual business requirements.
- The Launch of Resilience Hub: Several years ago, AWS introduced the original Resilience Hub to provide a centralized dashboard for resilience recommendations, helping customers define RTO and RPO targets.
- The Feedback Loop: Following the initial launch, user feedback indicated that while the tool was powerful, it was difficult to manage at scale. Large enterprises, in particular, struggled with the administrative overhead of managing thousands of services individually.
- The Next Generation: The current release marks the transition from a "per-application" tool to an "enterprise-wide" management platform. This shift was driven by the necessity for SRE teams to prove compliance during audits and the increasing complexity of distributed microservices architectures.
Supporting Data: Why This Matters for Modern Business
The necessity for such a robust tool is underscored by the current state of cloud operations. According to industry surveys, downtime costs for large-scale enterprise applications can exceed $10,000 per minute.

The new Resilience Hub tackles these costs by automating the "assessment" phase of the incident lifecycle. In a typical deployment, the manual discovery of dependencies alone can take days for an SRE team. By automating this, AWS is effectively reducing the "Mean Time to Discovery" (MTTD) for potential architectural flaws.
Furthermore, the integration with AWS Organizations provides a centralized view that is essential for compliance. For companies in highly regulated industries—such as banking, healthcare, or government—proving that an application meets a 99.99% availability requirement is a mandatory audit task. The new reporting features allow these organizations to generate compliance artifacts automatically, saving thousands of man-hours per year.
Official Responses and Strategic Implications
AWS leadership has positioned this release as a response to the growing maturity of their customer base. "Organizations running hundreds of applications share a common challenge: availability is a top concern, yet there is no consistent way to set resilience goals," said an AWS spokesperson during the announcement. "The next generation of AWS Resilience Hub changes this by giving SREs a structured way to align on expectations."
Implications for SREs and DevOps
For the SRE community, this release signals a move toward "Reliability as Code." By using the Resilience Hub console to define policies and then testing them against the architecture, teams can treat resilience with the same rigor as security and performance. The inclusion of "Failure Mode Guidance" is particularly impactful, as it provides a roadmap for engineers to simulate failures and build "self-healing" mechanisms into their code.
The Role of Generative AI
Perhaps the most significant addition is the use of AI to interpret complex topology maps. The system reads resources, maps connections, and builds a comprehensive visual graph. By then overlaying this with AI-generated assertions, the tool suggests fixes that a human architect might overlook, such as an incorrectly configured load balancer or a missing cross-region redundancy in a critical database layer.
Implementation: A Step-by-Step Approach
The transition to the new Resilience Hub is designed to be seamless, even for organizations with deeply entrenched workflows.
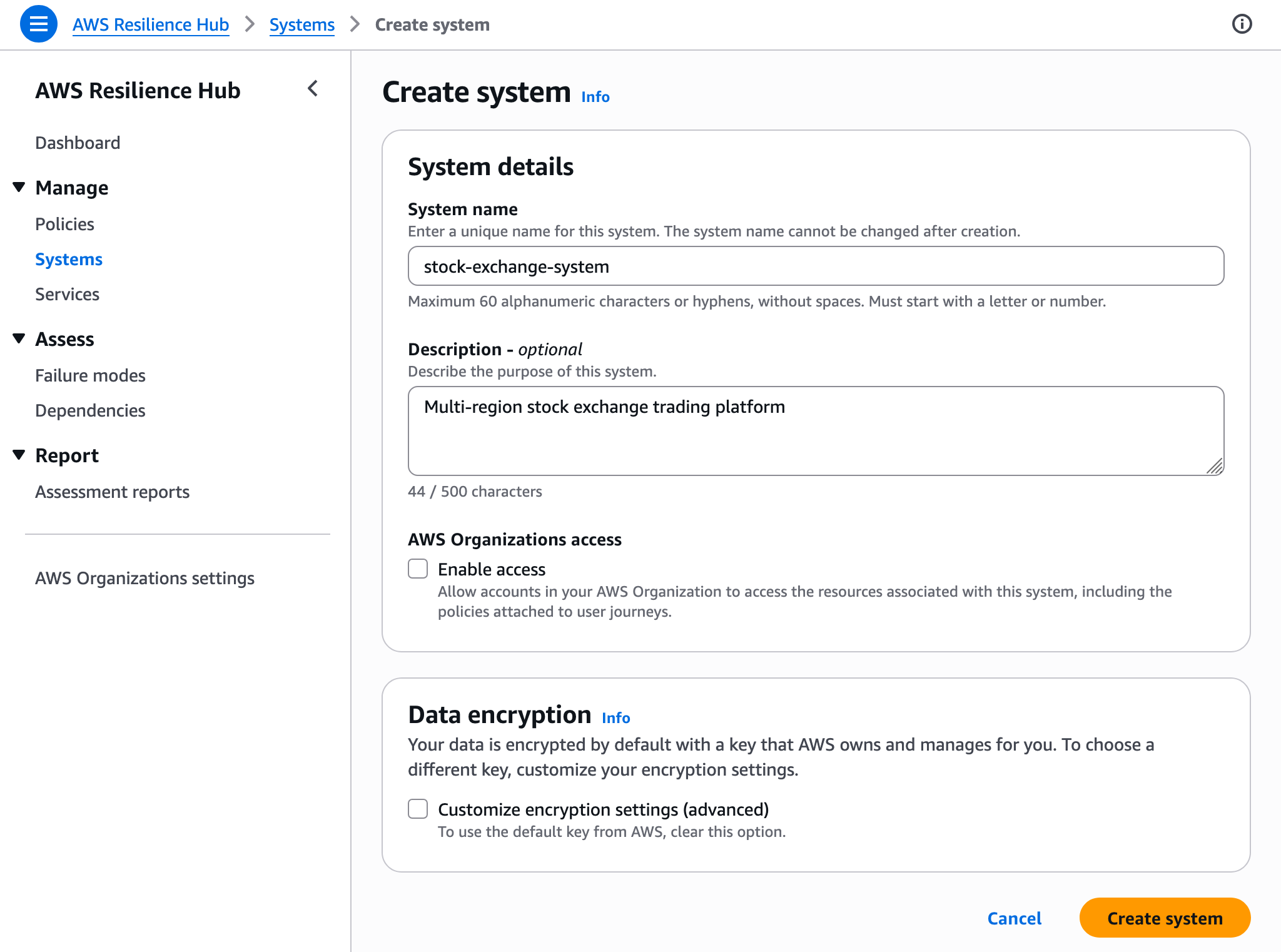
1. Configuration and IAM Roles
Before beginning, users must configure the "invoker" IAM role. This role is the heart of the security model, granting the Hub read-only access to scan resources across the enterprise. For organizations using multiple accounts, this role can be deployed at the organization level, allowing the central admin to see everything without compromising security boundaries.
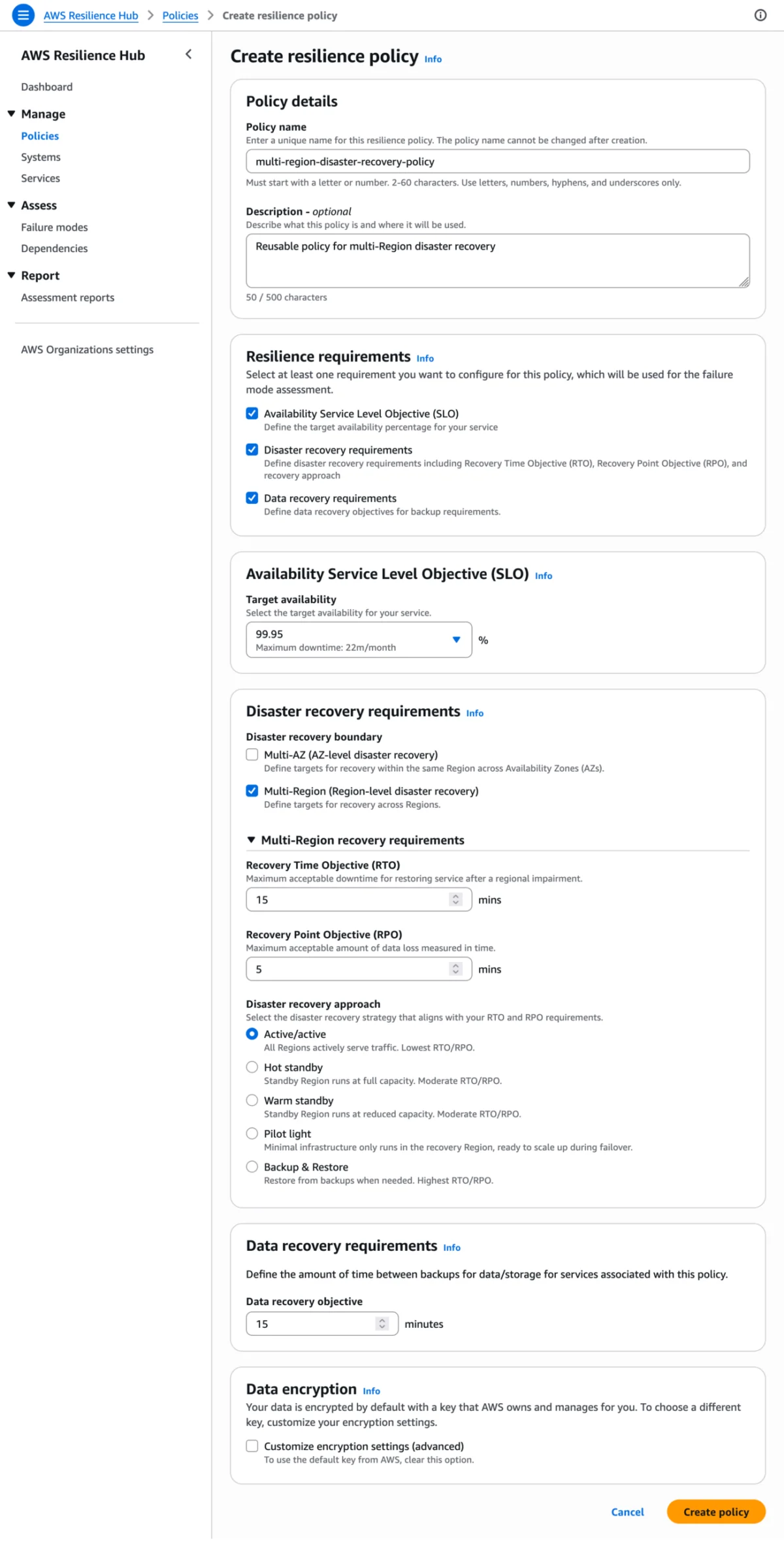
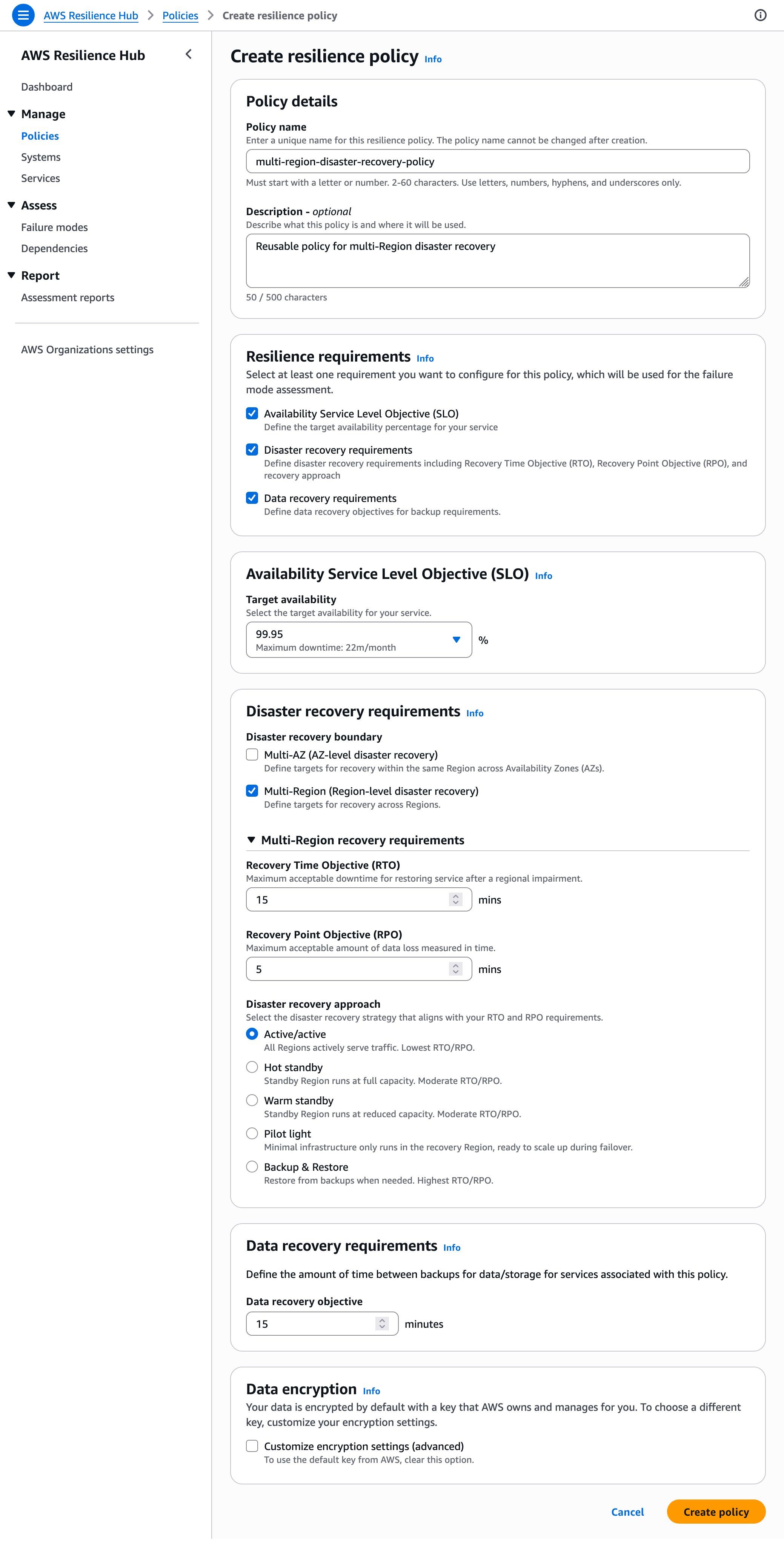
2. Defining the Policy
Users define their "Resilience Policy" by setting concrete objectives. For example, a "Gold Tier" policy might require:
- 99.95% Availability SLO.
- 15-minute RTO (Recovery Time Objective).
- 5-minute RPO (Recovery Point Objective).
- Multi-region disaster recovery mandates.
3. Service Discovery and Mapping
Once the policy is set, the user defines their services. The tool allows for various inputs, including Terraform state files, CloudFormation stacks, and even specific resource tags. Once the "Run Assessment" button is clicked, the system performs a deep dive, mapping the data flow and identifying potential single points of failure.
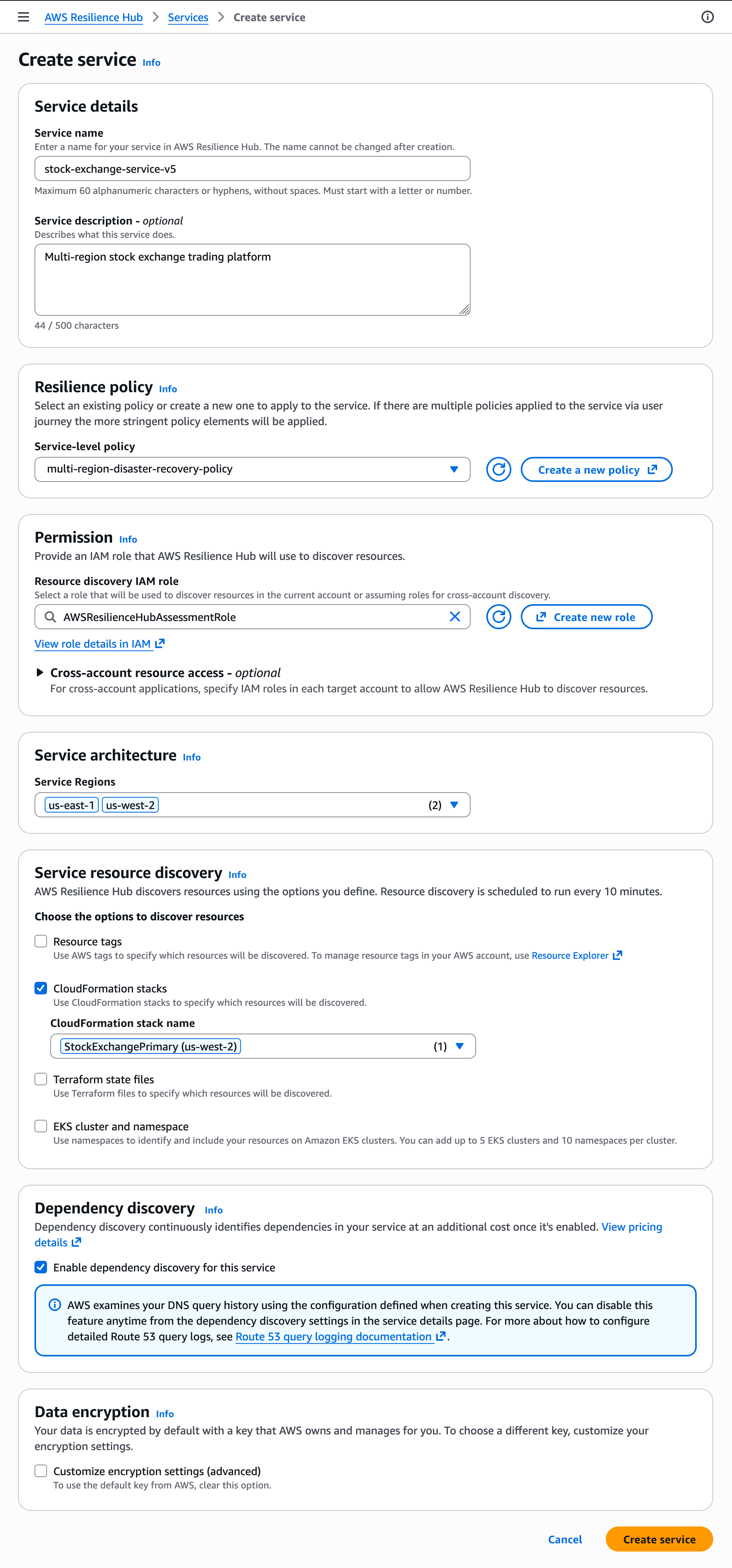
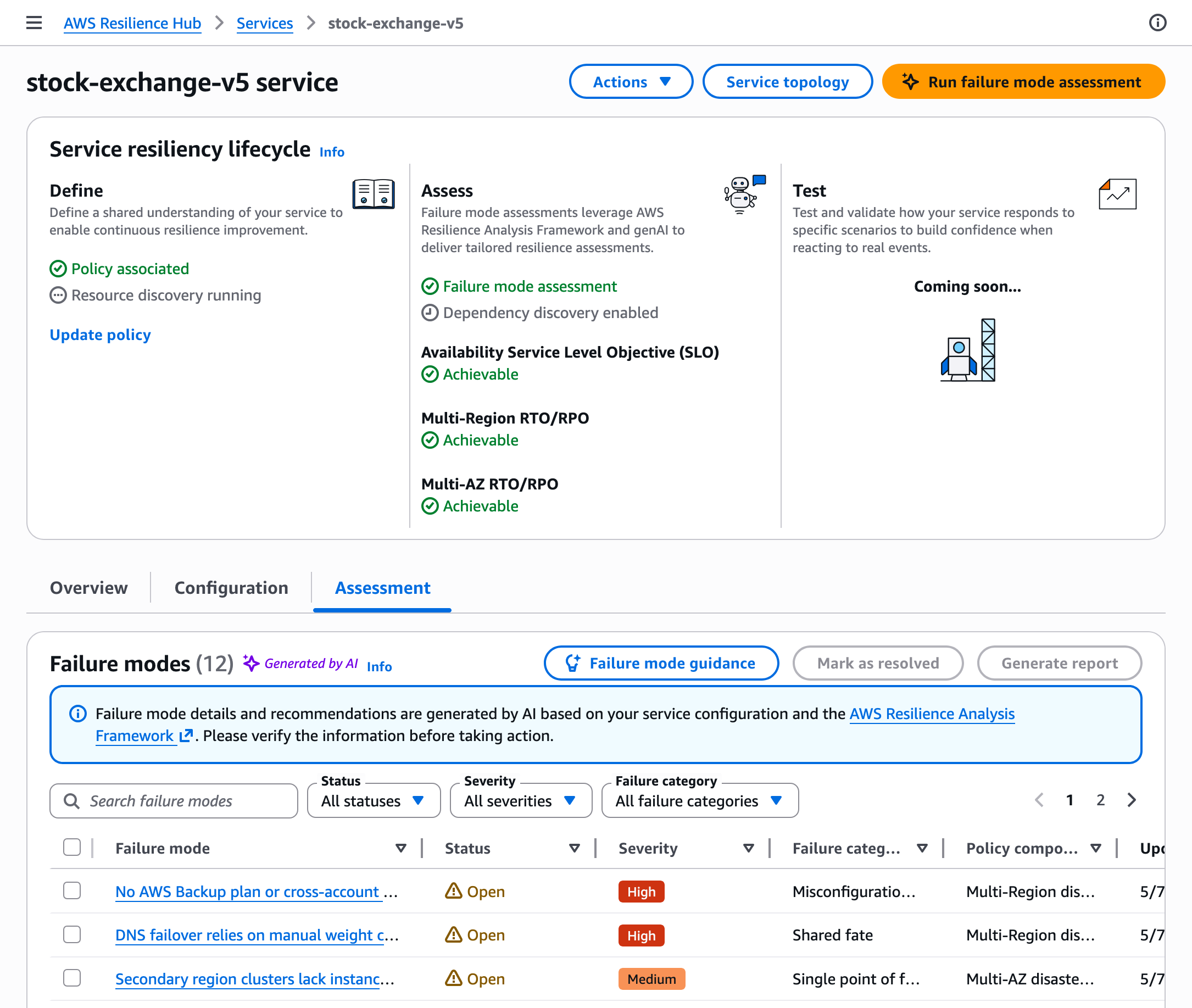
4. Remediation
The results tab is where the "heavy lifting" is validated. Each finding is prioritized by its impact on the policy. A finding might state: "The primary database lacks a cross-region read replica, violating your 15-minute RTO policy." The user can then mark this as resolved once the infrastructure team has implemented the fix, creating a clear audit trail.
Looking Ahead: The Future of Resilience
As AWS continues to evolve its service offerings, the next generation of Resilience Hub sets a new benchmark for what cloud service management should look like. The shift toward automated, AI-driven, and organization-wide visibility is likely to become the standard for the industry.
For organizations that have been hesitant to embrace large-scale cloud migration due to fears of "losing control" over reliability, this tool serves as a powerful assurance. It replaces the fear of the unknown with clear, measurable data.
As of this week, the service is generally available in all commercial AWS regions where the Resilience Hub is supported. With a new service-based pricing model that includes two free failure mode assessments per month, AWS is encouraging teams to experiment, iterate, and ultimately, build systems that are not just scalable, but truly resilient in the face of the inevitable failures that define modern computing.
In a world where digital experiences are the lifeblood of business, AWS has made it clear: if you aren’t measuring your resilience, you aren’t really in control of your infrastructure. This next-generation Hub provides the lens through which that control is finally achieved.