Revolutionizing Data Intelligence: Amazon S3 Introduces Native Annotation Capability
In an era where data is the lifeblood of artificial intelligence and machine learning, the ability to effectively catalog and retrieve information has become a critical bottleneck for enterprises. Today, Amazon Web Services (AWS) has unveiled a transformative update to its flagship storage service: Amazon S3 Annotations. This new capability allows organizations to attach rich, large-scale business context directly to their objects, effectively turning passive storage into an active, intelligent data lake.
This launch addresses a long-standing challenge in cloud architecture: the disconnect between massive, unstructured datasets and the metadata required to make that data actionable for AI agents and automated workflows.
The Core Innovation: What are S3 Annotations?
At its simplest, S3 Annotations provide a native mechanism to store structured or unstructured metadata—such as AI-generated summaries, technical specifications, or compliance labels—directly alongside S3 objects. Unlike previous metadata solutions that were limited by size and immutability, S3 Annotations offer a robust, flexible, and scalable framework.
Technical Specifications
- Capacity: Up to 1,000 named annotations per object.
- Scale: Each annotation can be up to 1 MB, allowing for 1 GB of metadata per object.
- Format Flexibility: Supports JSON, XML, YAML, and plain text.
- Mutability: Annotations can be updated, modified, or deleted without the need to rewrite the underlying object.
- Lifecycle Awareness: Annotations are bound to the object; they move automatically during replication or cross-region transfers and are purged when the object is deleted.
A Chronology of Metadata Evolution
The journey to S3 Annotations represents the latest chapter in a long evolution of how cloud storage handles descriptive data.
The Early Days: Rigid System Metadata
In the nascent stages of S3, metadata was strictly functional. System-defined metadata captured the "physical" properties of a file—size, storage class, and timestamp. It was immutable and insufficient for business logic.
The Era of Custom Headers (2 KB Limit)
As developers sought more control, AWS introduced user-defined metadata. However, this was constrained by a 2 KB limit, which forced engineers to store the bulk of their descriptive data in external databases or sidecar files. This created "data gravity" issues, where the metadata and the object were decoupled, leading to synchronization complexities.
The Rise of Object Tags
Object tags were introduced to help with operational tasks, such as access control and lifecycle management. While powerful for billing and security, they were never designed for rich descriptive context.

Today: The Annotation Paradigm
The introduction of S3 Annotations marks a paradigm shift. By moving the context inside the storage layer, AWS is effectively eliminating the need for complex, fragile, and costly "sidecar" databases. Organizations can now treat their S3 bucket as a self-describing, intelligent repository.
Supporting Data: Why Scale Matters
The limitations of previous metadata methods were not just inconvenient—they were costly. Maintaining a secondary database to track metadata for billions of S3 objects requires significant engineering overhead, latency-sensitive sync logic, and massive infrastructure costs.
| Capability | Max Size | Mutable | Best For |
|---|---|---|---|
| System Metadata | Fixed | No | Size, Class, Time |
| User Metadata | 2 KB | No | Small Key-Value Pairs |
| Object Tags | 10 Tags | Yes | Security/Lifecycle |
| Annotations | 1 GB | Yes | AI/Business Context |
The ability to store 1 GB of metadata per object is not merely a quantitative upgrade; it is a qualitative one. For instance, a high-resolution video file can now carry its entire transcript, scene-detection metadata, and copyright information within the object itself. When this is scaled across a petabyte-scale data lake, the computational savings from not having to query external databases are profound.
Implications for the AI Economy
The most significant impact of this update is the enablement of "Agentic Workflows." As organizations deploy autonomous AI agents to parse vast datasets, those agents require a way to understand the content without performing resource-heavy "deep reads" of the actual files.
AI Discovery through S3 Tables
By enabling S3 Metadata annotation tables, users can leverage Amazon Athena to query their annotations as if they were rows in a standard database. Because these tables are built on the Apache Iceberg open table format, they offer near-infinite scalability and interoperability with various analytics engines.
The Role of the S3 Tables MCP Server
AWS is also integrating the S3 Tables Model Context Protocol (MCP) server. This allows AI agents to interact with data using natural language. An agent can be instructed to "find all video files with specific sentiment scores and high-resolution formatting." Because the annotation table is indexed and queryable, the agent can retrieve the list of objects in seconds, bypassing the need to crawl the raw data.
Official Perspective and Implementation
Daniel Abib, representing the AWS S3 team, emphasized that this feature was built specifically to remove the "heavy lifting" of metadata management. The implementation process is designed to be developer-friendly, utilizing the existing AWS CLI and SDKs.

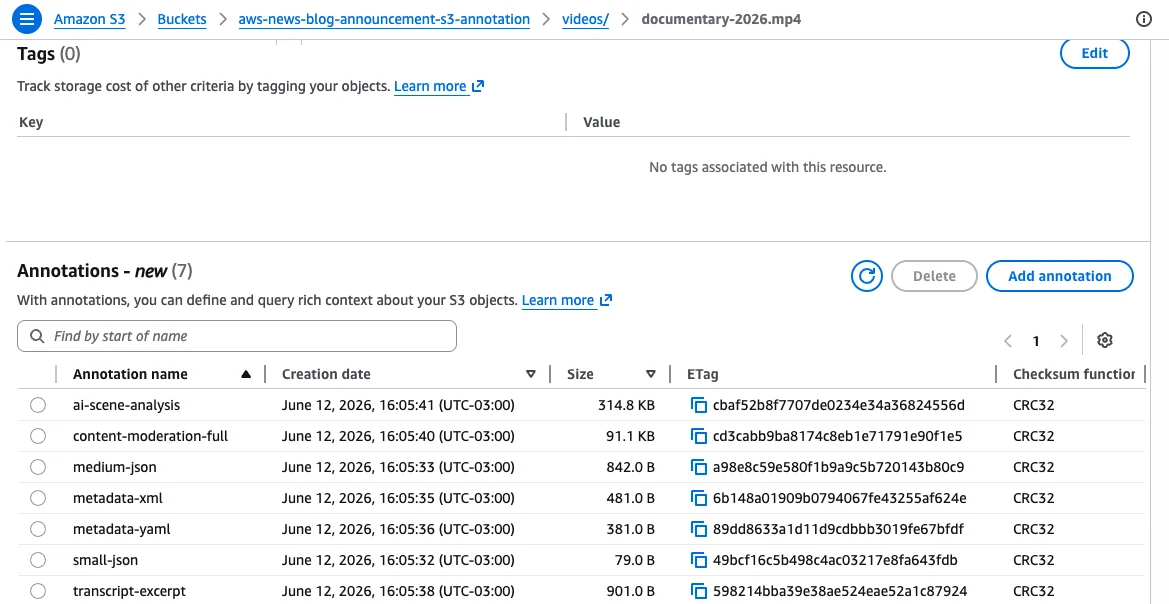
Developer Workflow Example
For a media company, adding technical specifications to a video file is now a simple API call.
# Example: Attaching a JSON specification
aws s3api put-object-annotation
--bucket my-media-bucket
--key videos/documentary-2026.mp4
--annotation-name mediainfo
--annotation-payload ./mediainfo.jsonThis command demonstrates the ease of use. Once the annotation is attached, it becomes part of the object’s metadata ecosystem, ready for immediate indexing into an annotation table.
Strategic Implications for Industry Verticals
Media and Entertainment
Media companies manage massive libraries of content. Previously, tracking metadata like "audio tracks," "frame rate," or "language tags" required complex, synchronized databases. With Annotations, this data lives with the file. During distribution, the file and its metadata travel together, ensuring that downstream systems always have the correct technical context.
Healthcare and Life Sciences
In genomics or medical imaging, patient data must be highly secure and meticulously described. Annotations allow researchers to attach clinical findings, patient IDs (where compliant), and study identifiers directly to imaging files. This keeps the data self-contained and simplifies the process of auditing and compliance.
Financial Services
Financial institutions utilize vast amounts of archived data for regulatory compliance. Annotations allow for the attachment of "compliance tags" or "deletion policies" to specific datasets. When auditors request proof of data management, firms can query their annotation tables to produce precise reports without performing massive scans of the storage layer.
Overcoming the "Sidecar" Bottleneck
Historically, organizations built "sidecar" files—small text or JSON files stored next to the main data—to hold metadata. This created several operational risks:
- Consistency: The risk that a sidecar file becomes disconnected from the object.
- Performance: The need to read two objects instead of one.
- Cost: Storage and retrieval fees for two separate entities.
By migrating to S3 Annotations, companies can decommission these sidecar systems. This results in cleaner, more manageable architecture and a reduction in the "operational tax" associated with maintaining secondary metadata infrastructure.
Future Outlook: The Intelligent Data Lake
The introduction of S3 Annotations suggests that AWS is moving toward a future where the distinction between "data" and "metadata" is increasingly blurred. As AI models become more sophisticated, the volume of metadata generated will continue to climb. By providing a native home for this information, AWS is positioning itself as the infrastructure backbone for the next generation of intelligent, automated enterprise applications.
For companies currently struggling with the complexity of data discovery, the call to action is clear. By transitioning to S3 Annotations, they can reduce latency, lower costs, and unlock the full potential of their data for AI-driven insights.
Getting Started
Users can begin using S3 Annotations immediately across all AWS regions. To get started, organizations should:
- Review IAM Policies: Ensure the
s3:PutObjectAnnotationands3:GetObjectAnnotationpermissions are correctly configured. - Enable Annotation Tables: Use the S3 Console or the
CreateBucketMetadataConfigurationAPI to begin indexing annotations into queryable tables. - Refactor Workflows: Begin moving metadata from legacy databases into native S3 Annotations to take advantage of the performance and integration benefits.
As the industry moves toward more autonomous, agent-led operations, the ability to effectively "tag" and "index" the world’s data will be the ultimate competitive advantage. With this latest update, AWS has provided the tools necessary to make that vision a reality.